Run Experiments
The functionality to train your model and run experiments with different hyperparameters or datasets is currently disabled in DVC Studio. However, DVC experiments that are created from the terminal or the VS Code extension can be monitored and managed from DVC Studio.
Monitor a running experiment
Once you submit an experiment, a new row is created in the experiments table under the original Git commit. Live updates to metrics and plots generated by DVCLive will show up in this row, and you can click on the experiment name to view the status and output log of the running experiment task.
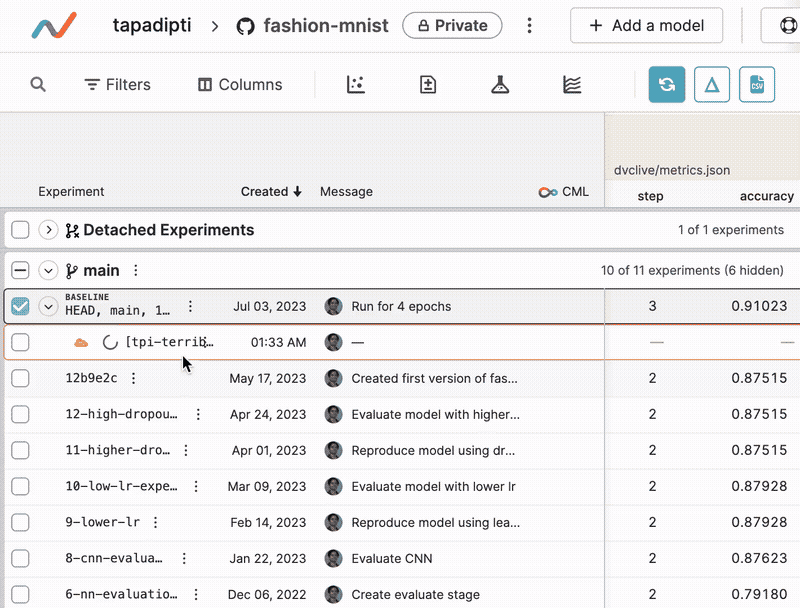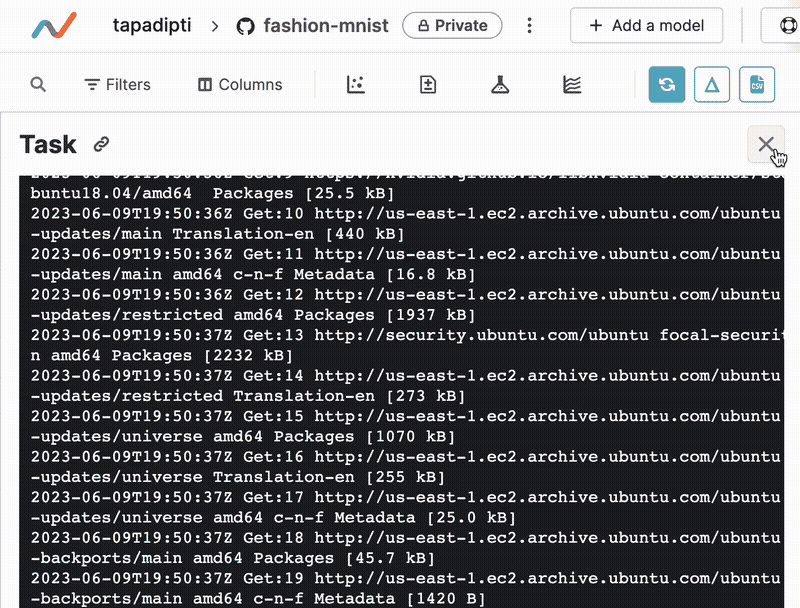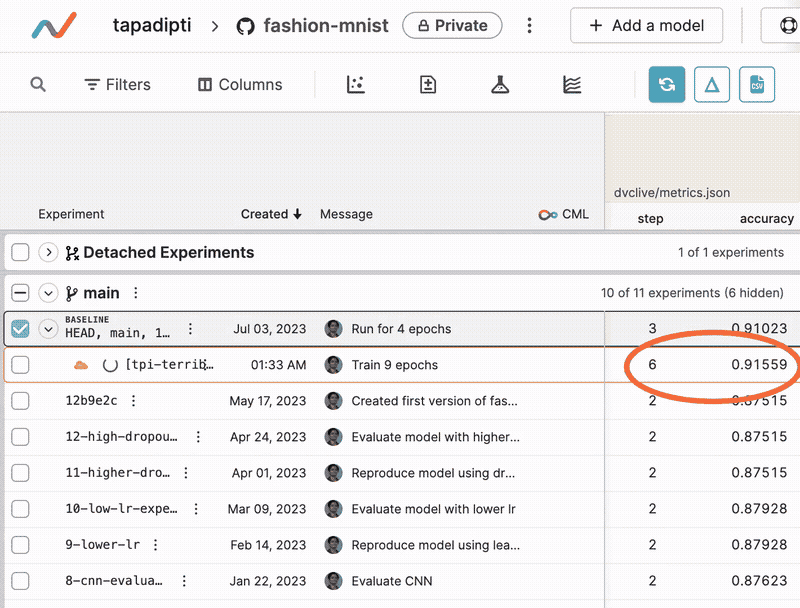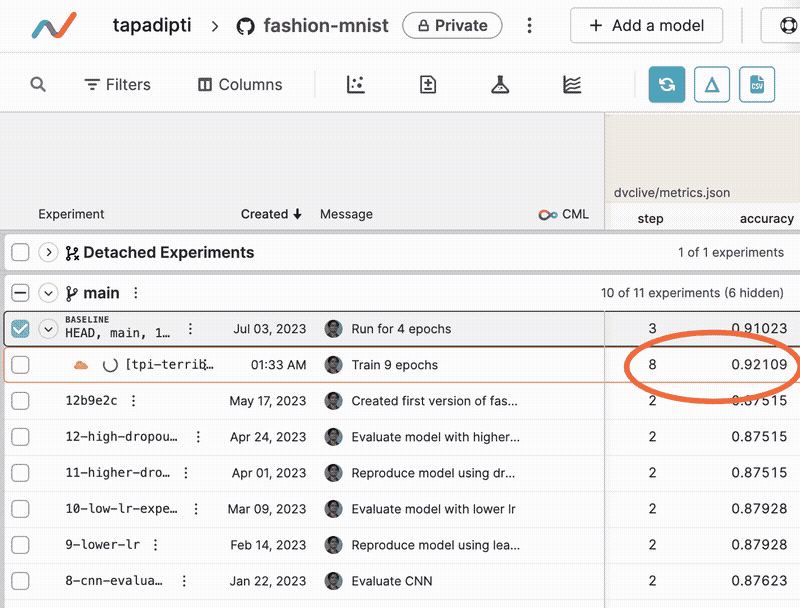
Manage a completed experiment
When the experiment completes, the files (including code, data, models, parameters, metrics, and plots) are pushed back to your Git and DVC remotes.
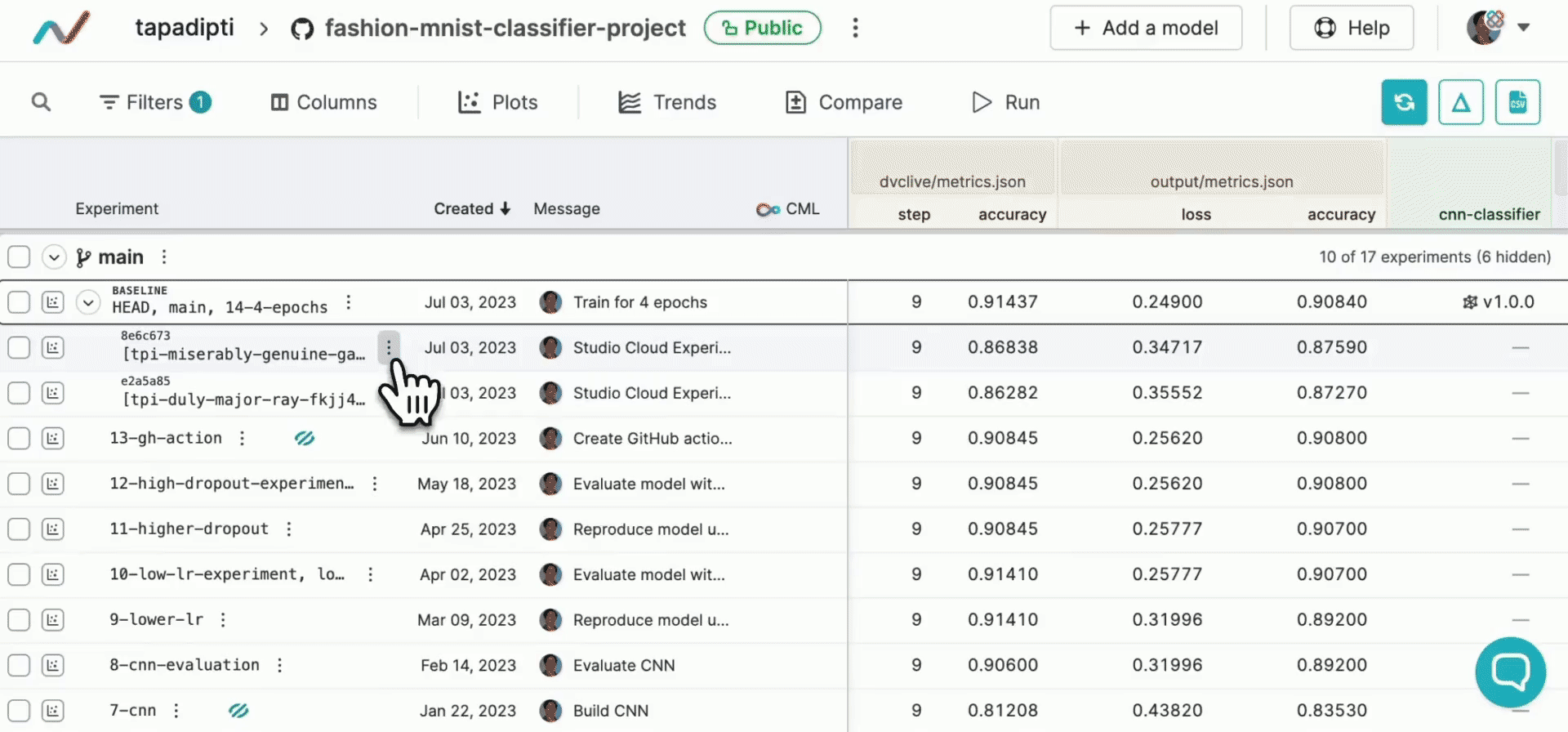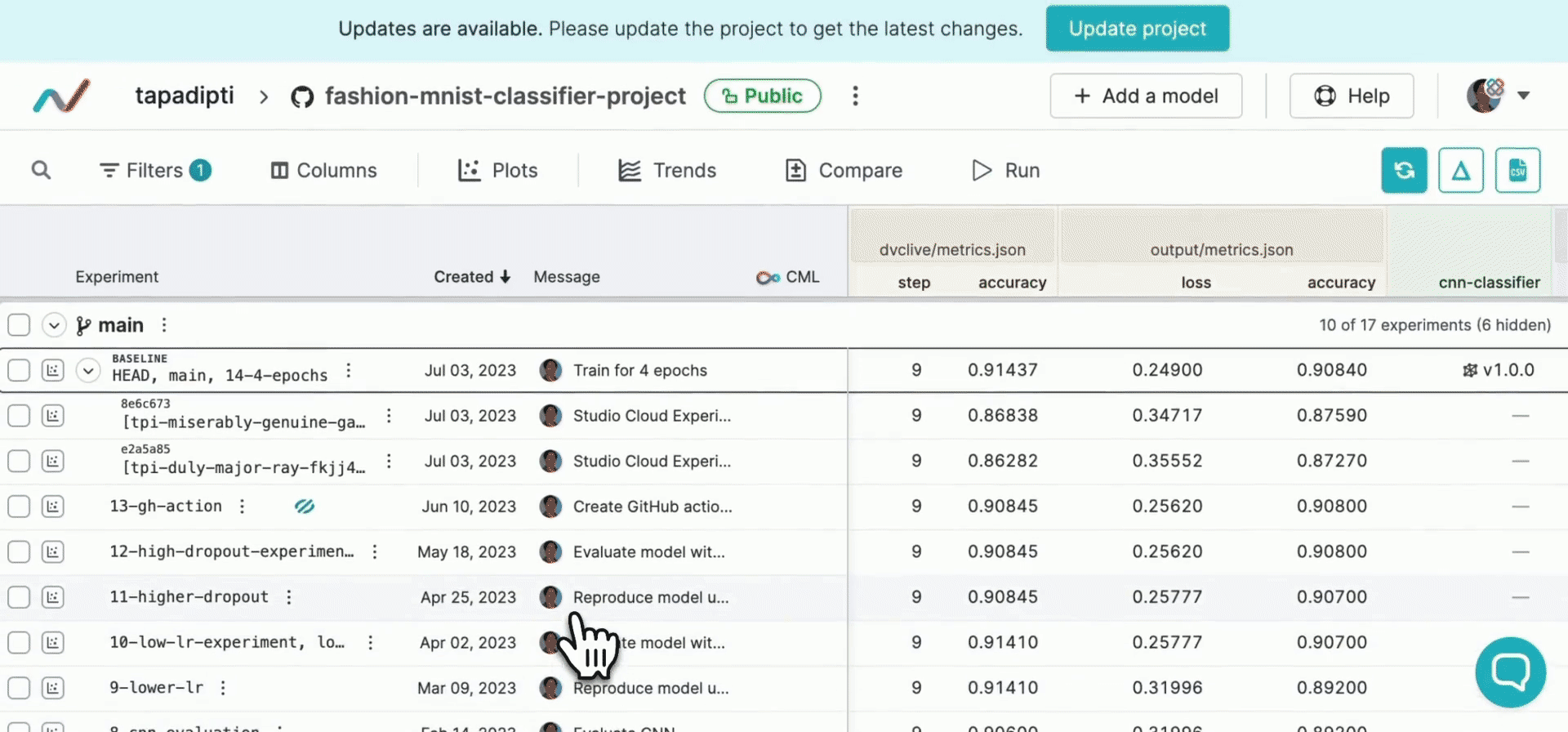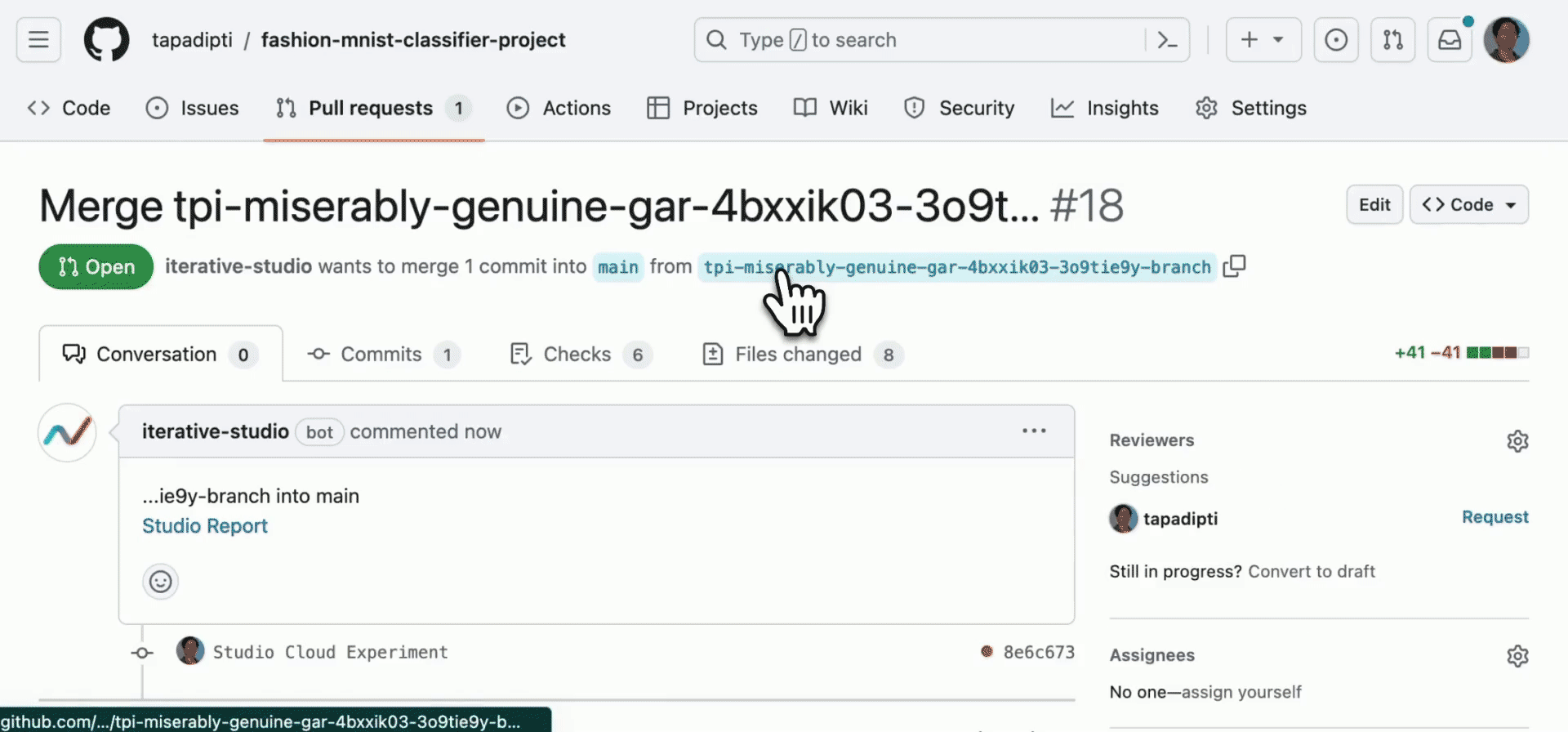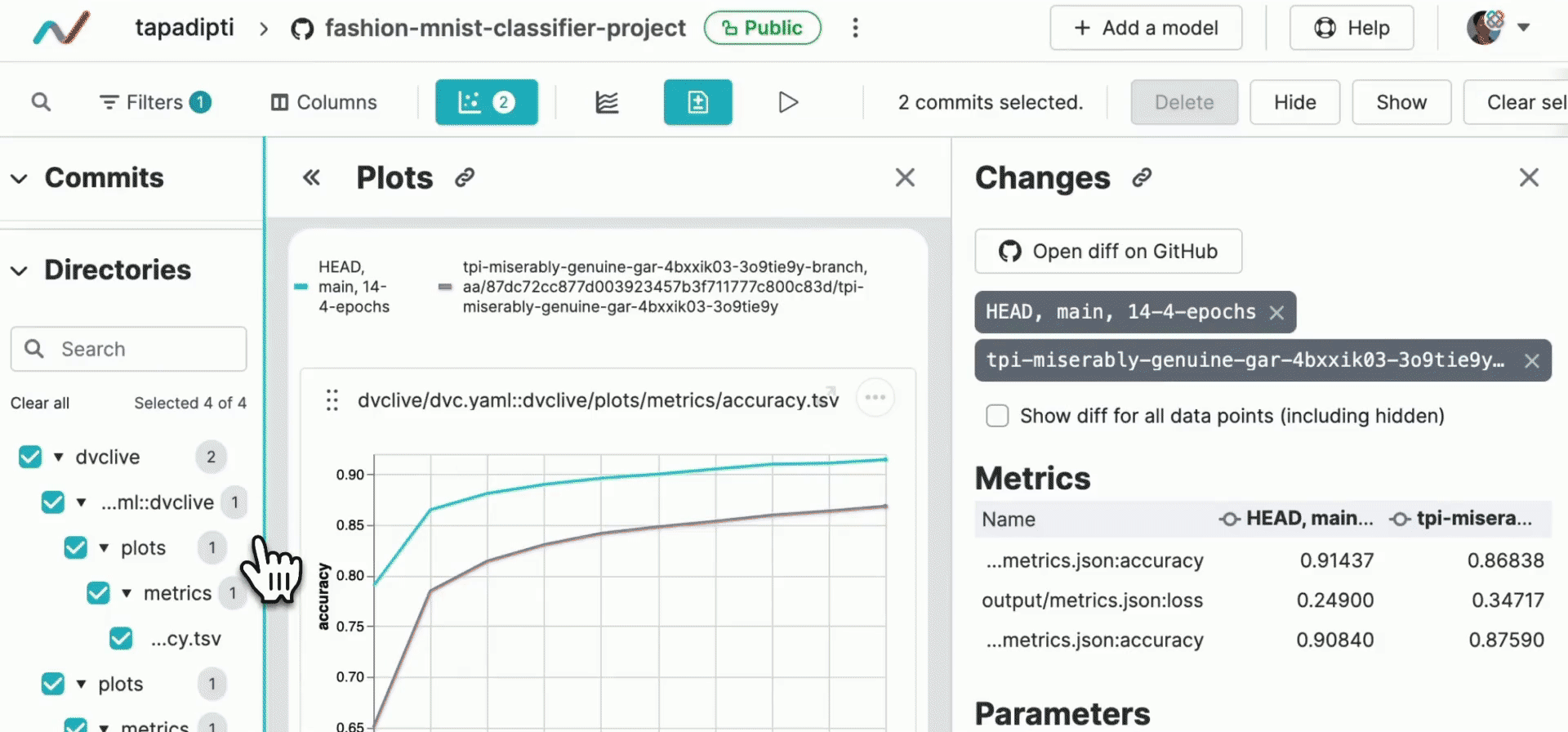
In DVC Studio, you can create a branch and pull/merge request from the completed experiment, so that you can share, review, merge, and reproduce the experiment. In the pull/merge request, DVC Studio automatically inserts a link to the training report. So your teammates who are reviewing your PR can quickly and easily compare your experiment with its baseline.