Running Experiments
We explain how to execute DVC experiments, setting their parameters, queueing them for future execution, running them in parallel, among other details.
This page is not applicable if you are saving experiments without a pipeline.
If this is the first time you are introduced to DVC experimentation, you may want to check the basics in Get Started: Experiments first.
Running experiment commands and pipelines
DVC relies on dvc.yaml files that contain the commands to run the
experiment(s). These files codify pipelines that specify one or more
stages of the experiment workflow (code, dependencies,
outputs, etc.).
See Get Started: Experimenting Using Pipelines for an intro to this topic.
Running the pipeline(s)
You can run the experiment pipelines using dvc exp run. It uses
./dvc.yaml (in the current directory) by default.
$ dvc exp run
...
Reproduced experiment(s): matte-viesLook for the Run experiment icon in any of the available menus and click to
run:
DVC observes the dependency graph between stages, so it only runs the ones
with changed dependencies or outputs missing from the cache. You
can limit this to certain reproduction targets or even single stages
(--single-item flag).
DVC projects actually support more than one pipeline, in one or
more dvc.yaml files. The --all-pipelines option lets you run them all at
once.
dvc exp run is an experiment-specific alternative to dvc repro. See Running
Pipelines for differences between them.
Experiment results
The results of the last dvc exp run can be seen in the workspace.
They are stored and tracked internally by DVC.
To display and compare multiple experiments along with their
parameters and metrics, use dvc exp show.
dvc plots diff also accepts experiments as revisions. See Reviewing and
Comparing Experiments for more details.
Use dvc exp apply to restore the results of any other experiment instead. See
Bring experiment results to your workspace for more info.
Only files tracked by either Git or DVC are saved to the experiment. Untracked files cannot be restored.
Tuning (hyper)parameters
Parameters are any values used inside your code to tune modeling attributes, or that affect experiment results in any other way. For example, a random forest classifier may require a maximum depth value. Machine learning experimentation often involves defining and searching hyperparameter spaces to improve the resulting model metrics.
Your source code should read params from structured parameters files
(params.yaml by default). Define them with the params field of dvc.yaml
for DVC to track them. When a param value has changed, dvc exp run invalidates
any stages that depend on it, and reproduces them.
See dvc params for more details.
You could manually edit a params file and run an experiment using those as
inputs. Since this is a common sequence, the built-in option
dvc exp run --set-param (-S) is provided as a shortcut. It takes an existing
param name and value, and updates the file on-the-fly before execution.
$ cat params.yaml
...
train:
valid_pct: 0.1
arch: shufflenet_v2_x2_0
img_size: 256
batch_size: 8
fine_tune_args:
epochs: 8
base_lr: 0.01
...
$ dvc exp run --set-param train.fine_tune_args.base_lr=0.001
...
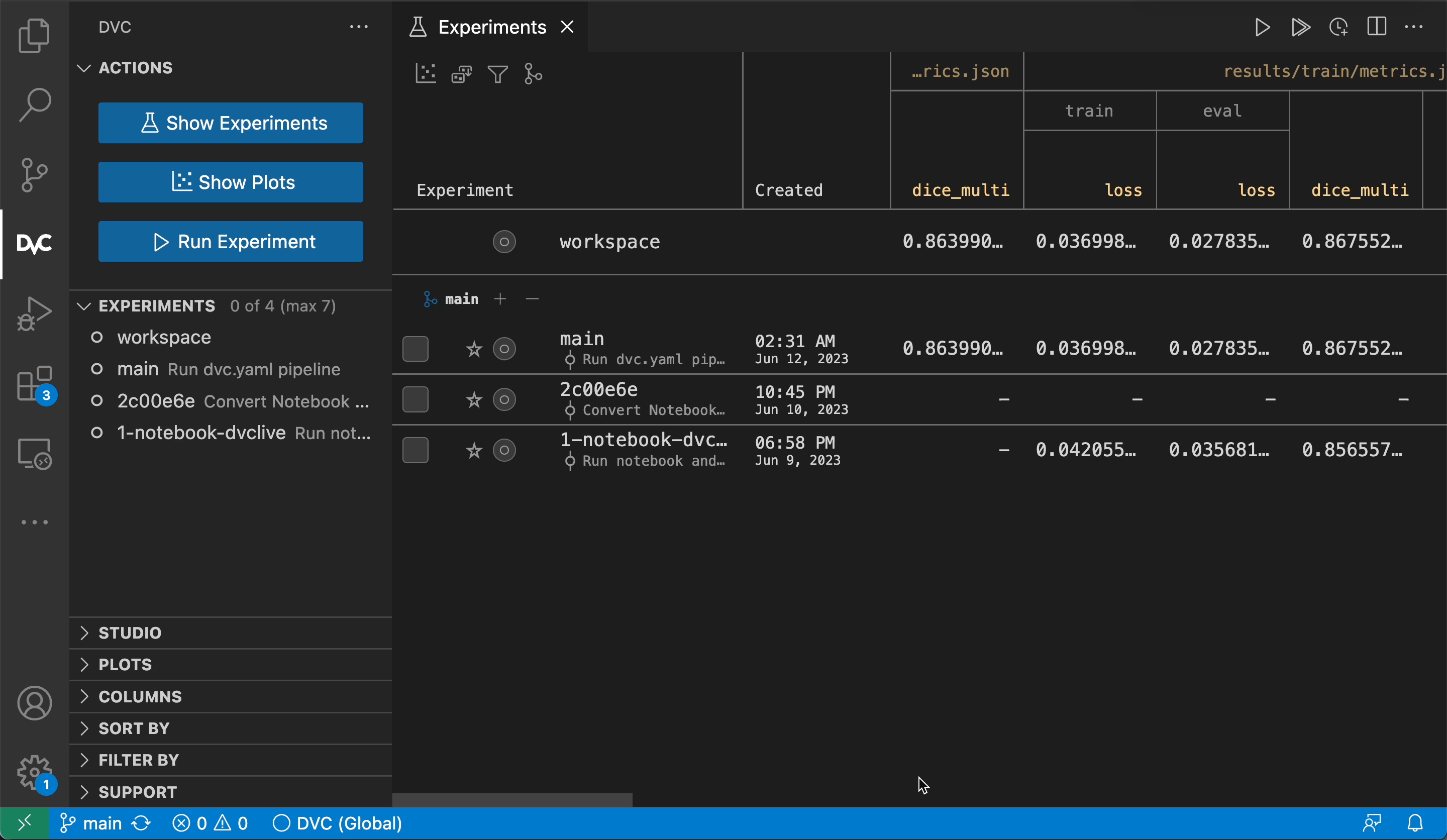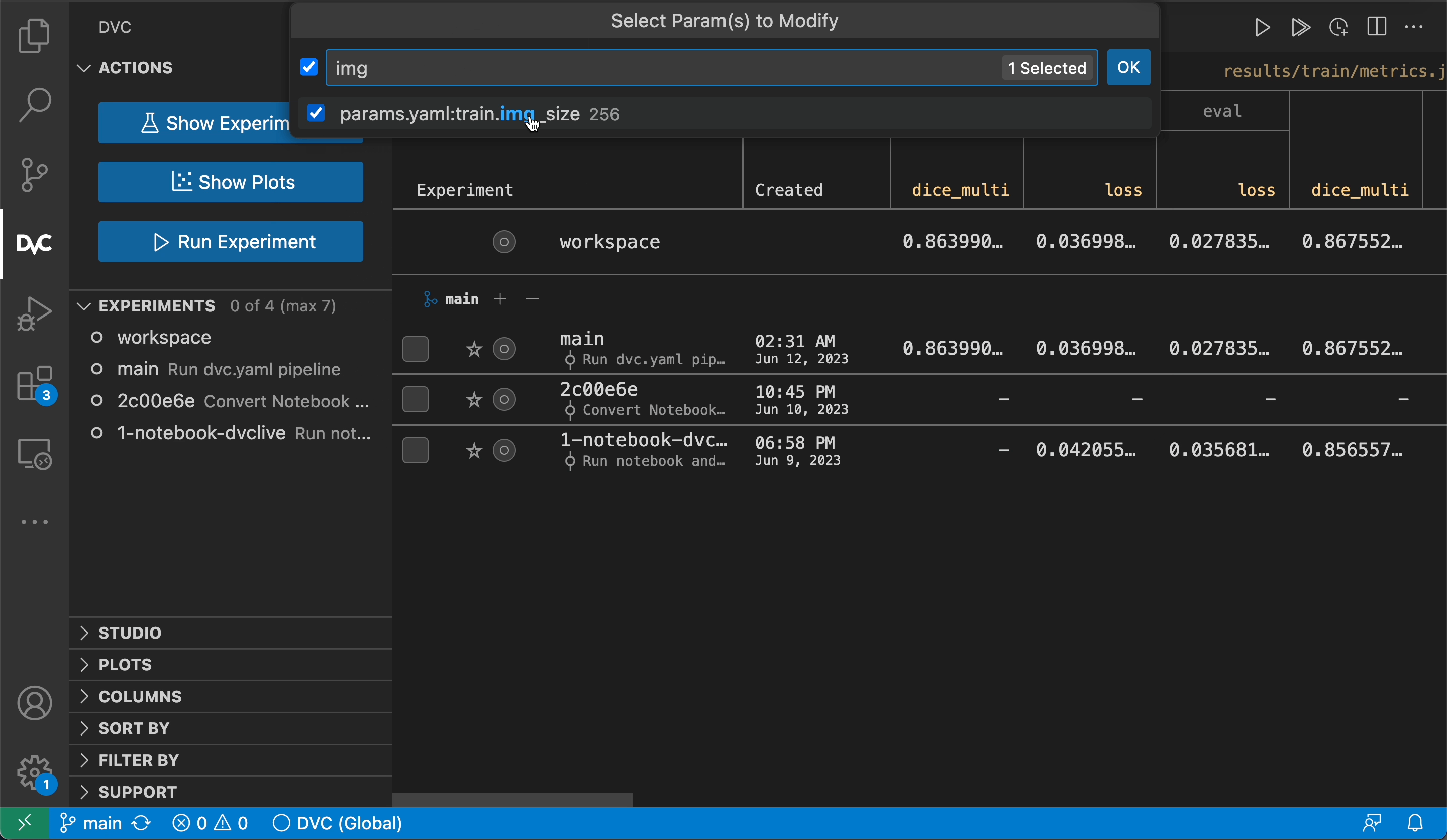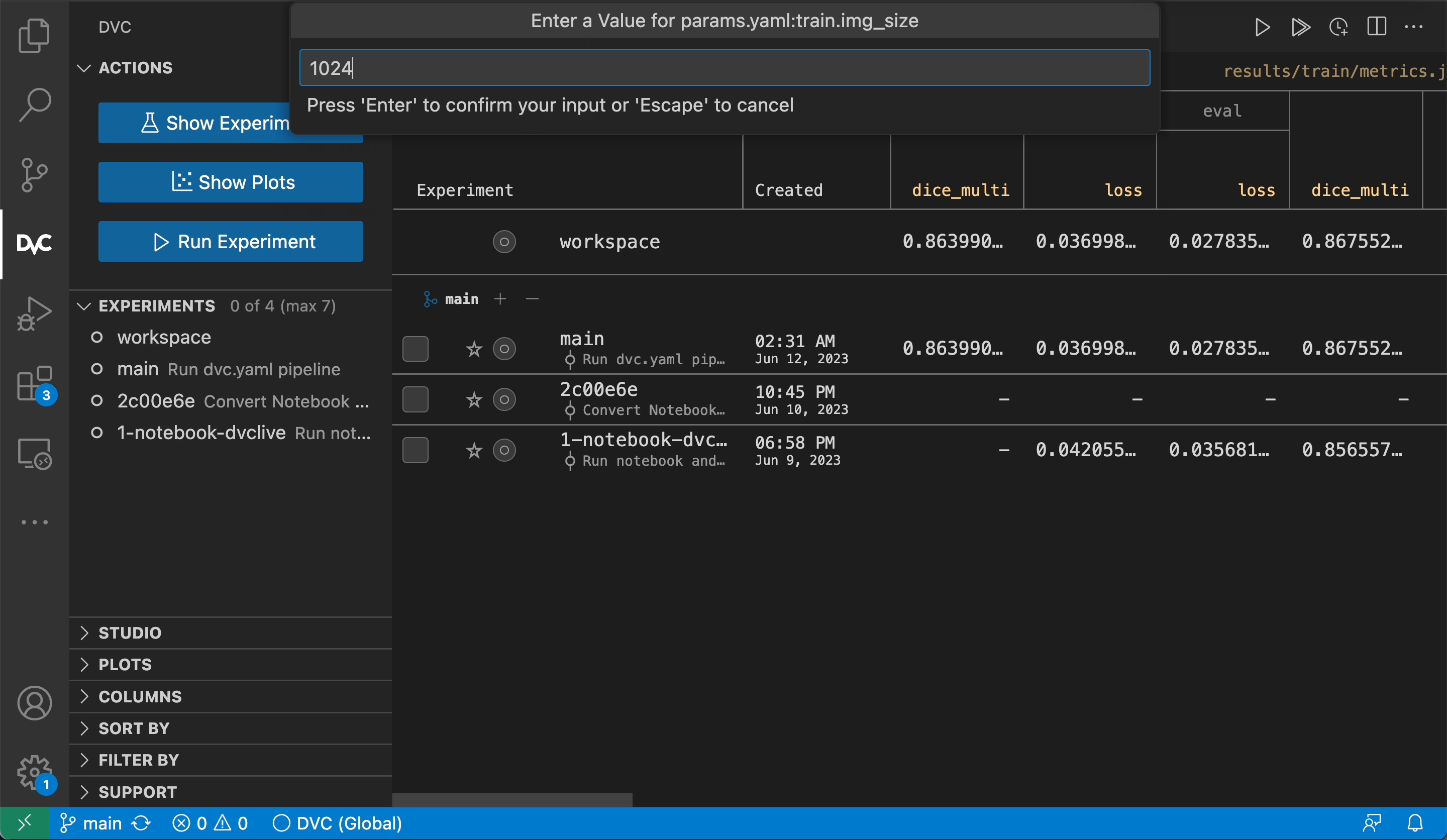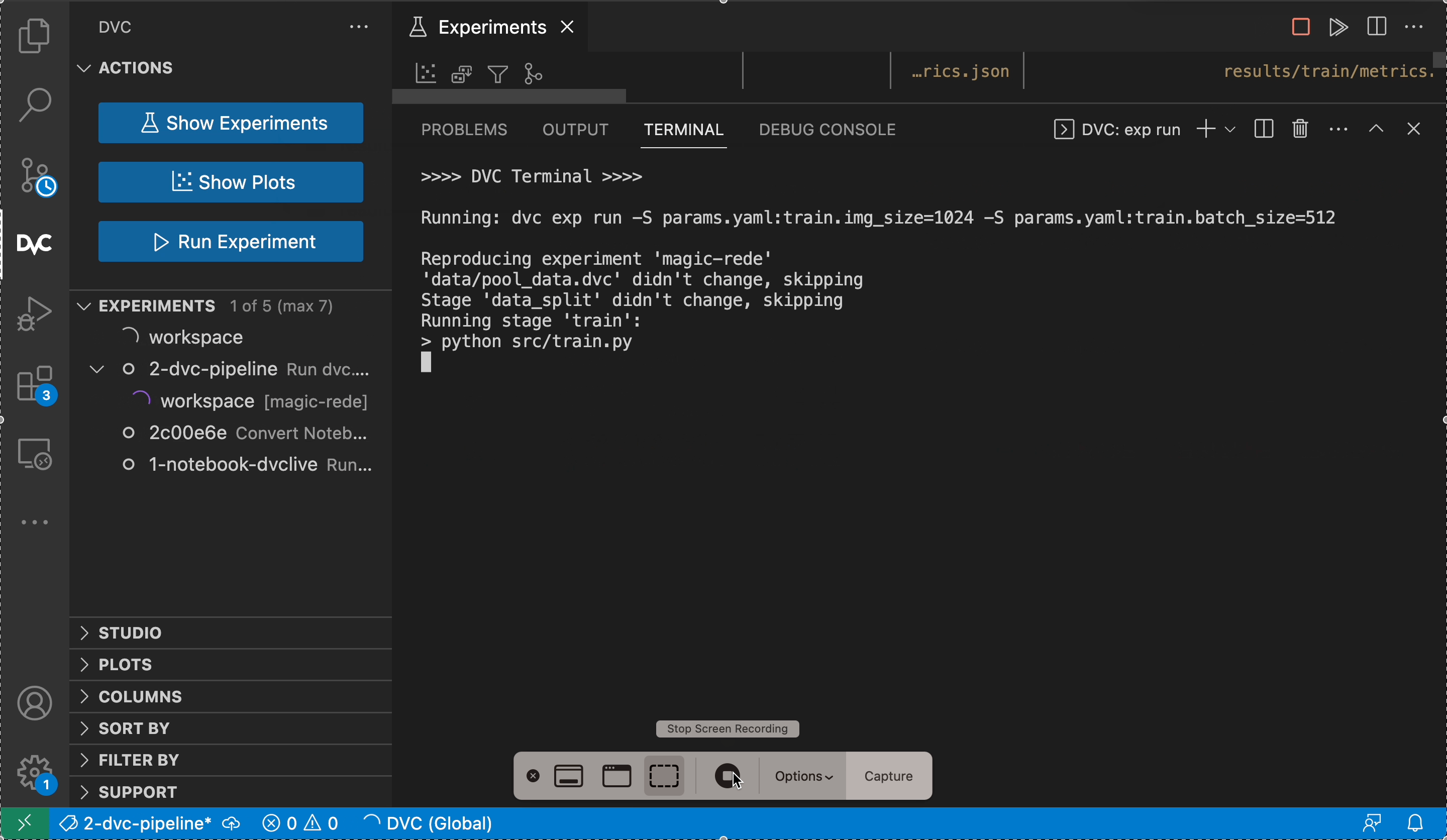
$ dvc exp run -S train.img_size=1024 -S train.batch_size=512 # set multiple params
...
See Hydra composition for more advanced configuration options via parameter overrides (change, append, or remove, or use "choice" sets and ranges).
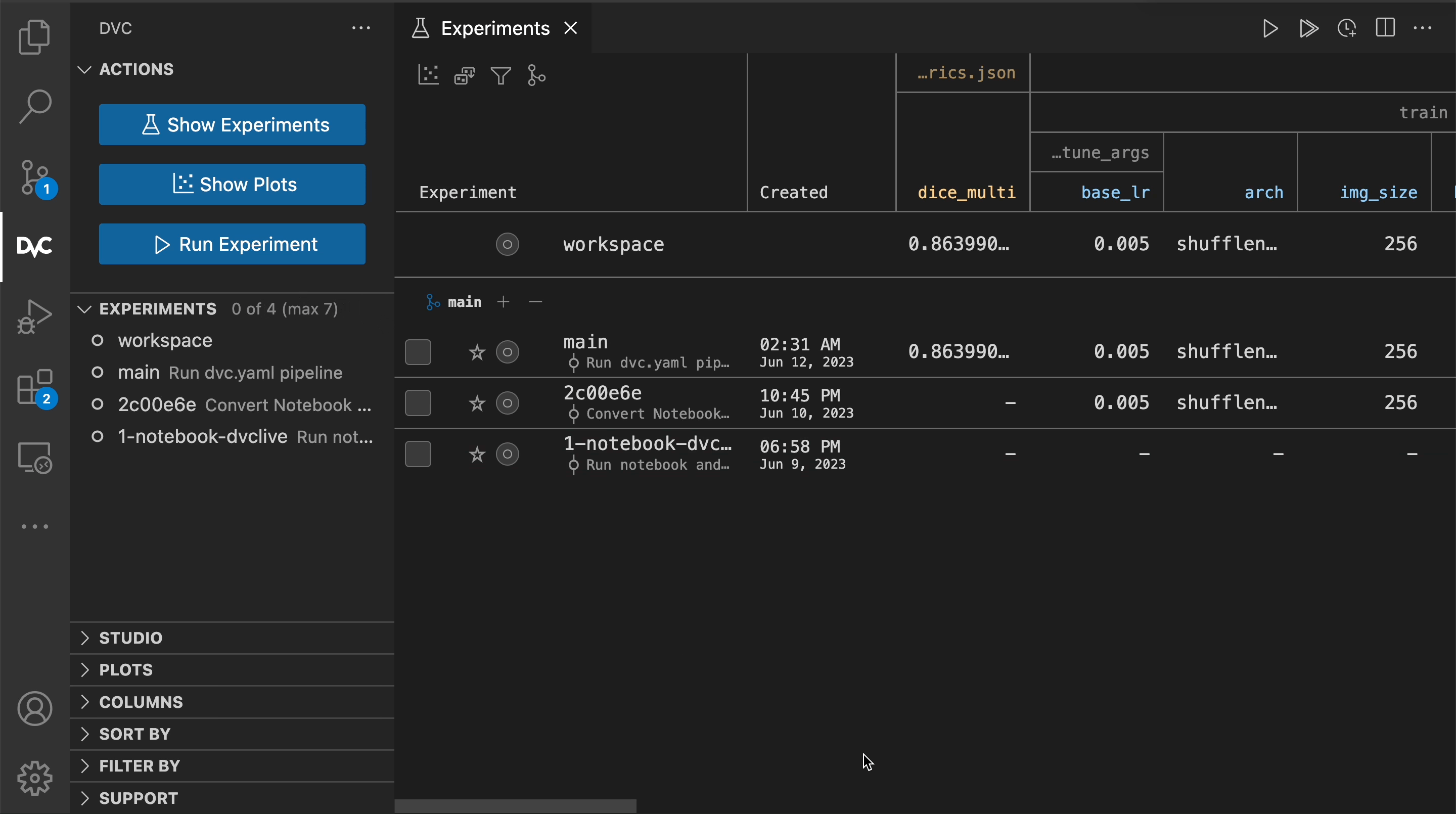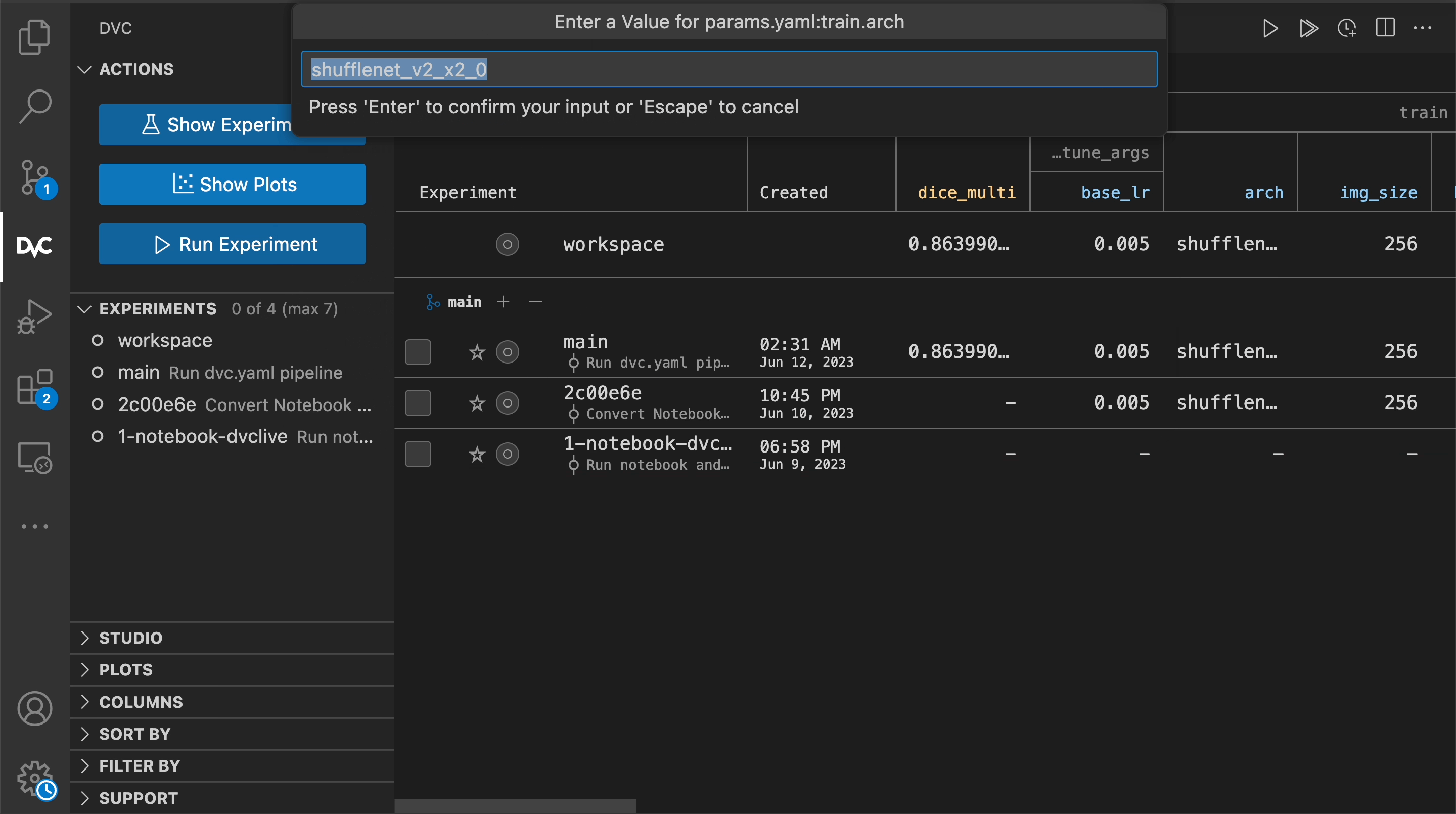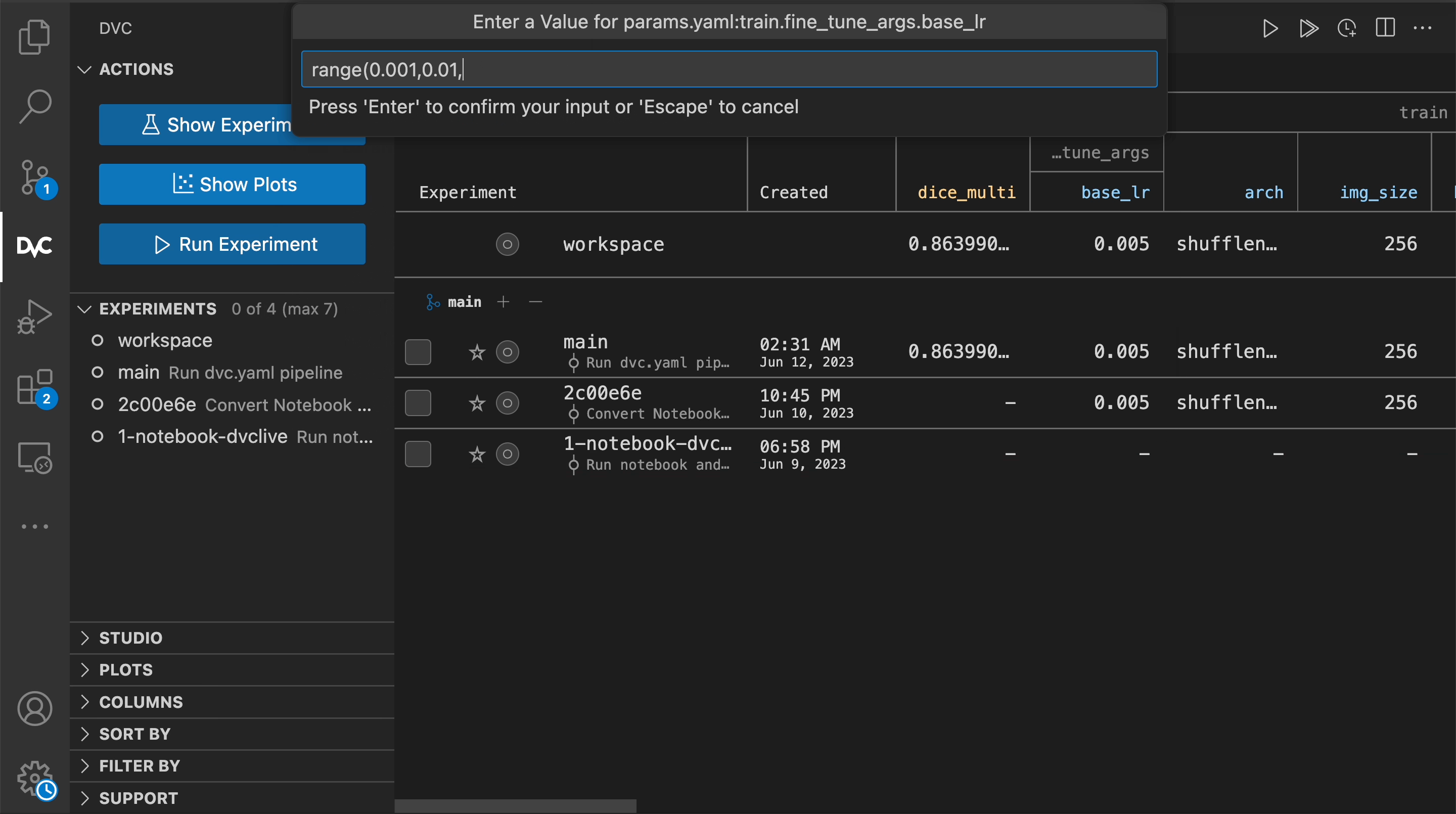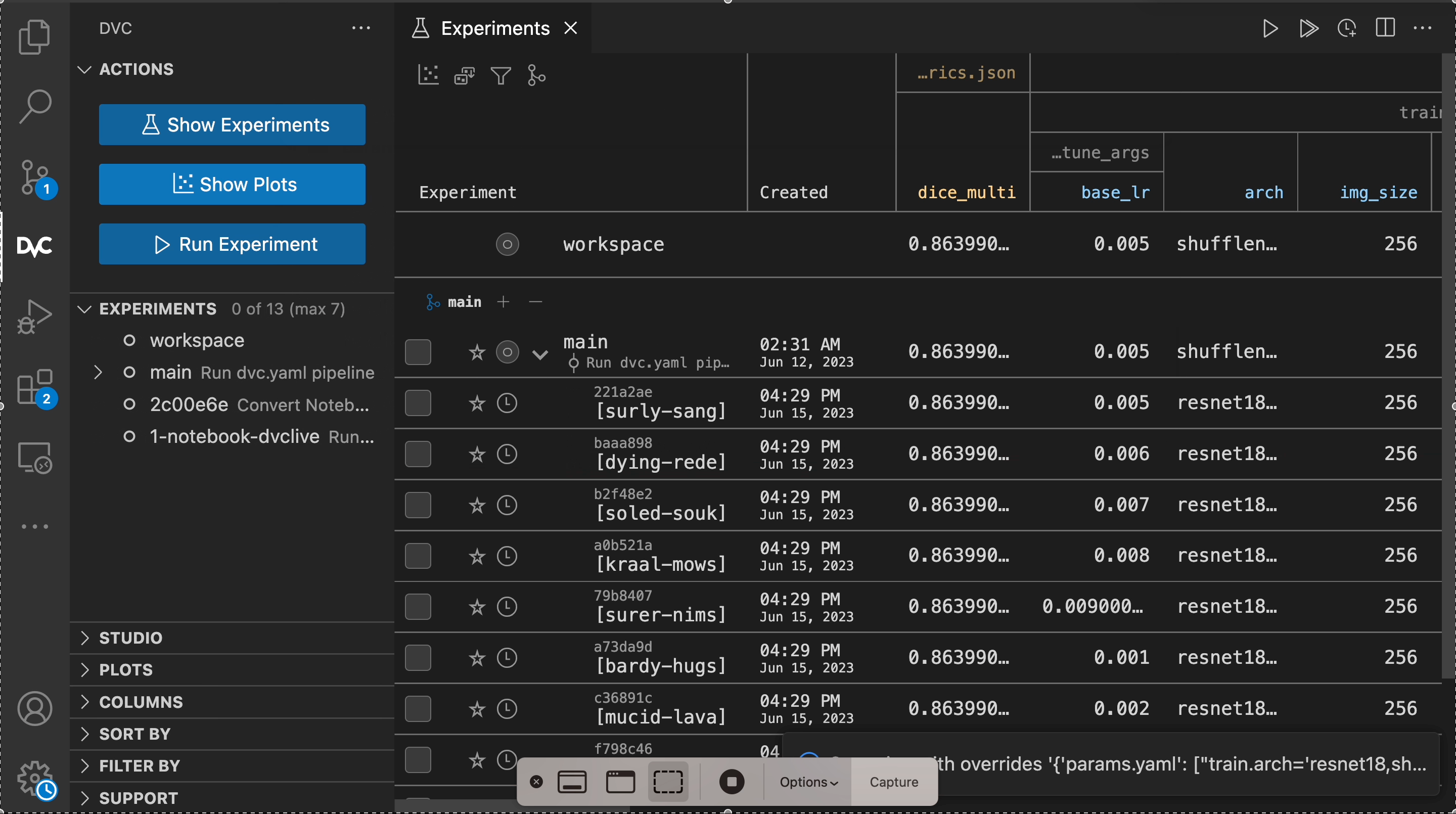
The experiments queue
The --queue option of dvc exp run tells DVC to append an experiment for
later execution. Nothing is actually run yet. Let's queue a couple experiments:
$ dvc exp run --queue -S train.fine_tune_args.base_lr=0.001
Queueing with overrides '{'params.yaml': ['train.fine_tune_args.base_lr=0.001']}'.
Queued experiment 'blowy-pail' for future execution.
$ dvc exp run --queue -S train.fine_tune_args.base_lr=0.002
Queueing with overrides '{'params.yaml': ['train.fine_tune_args.base_lr=0.002']}'.
Queued experiment 'nubby-gram' for future execution.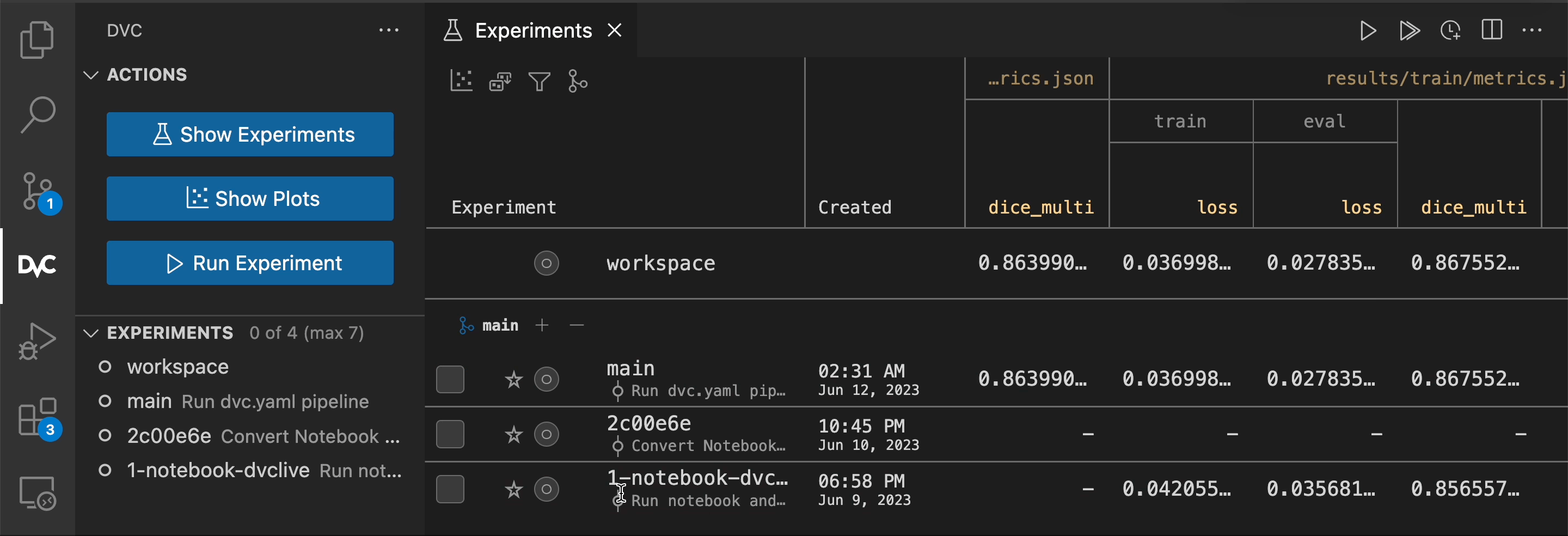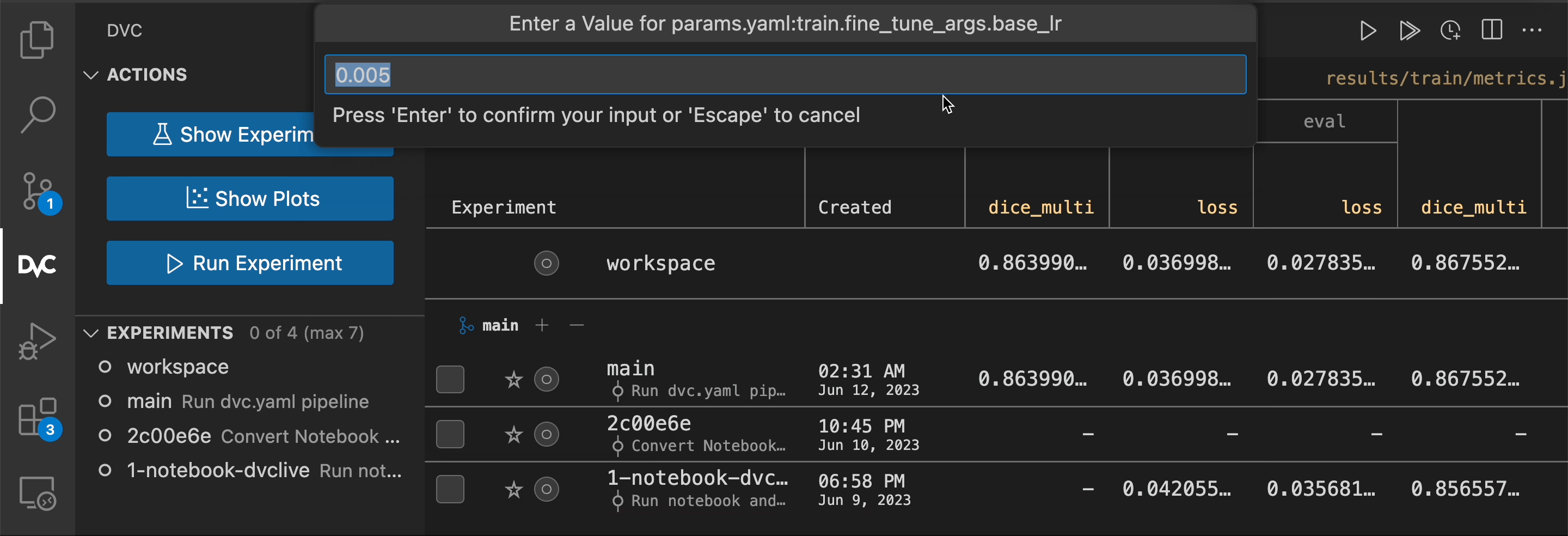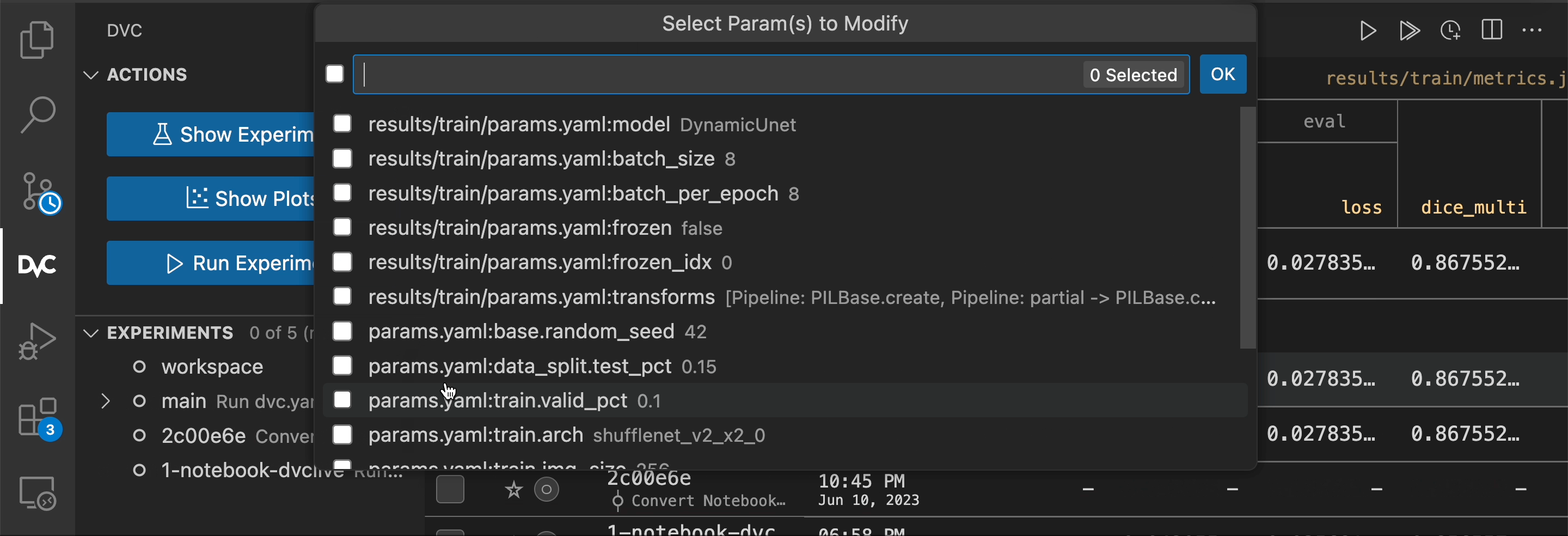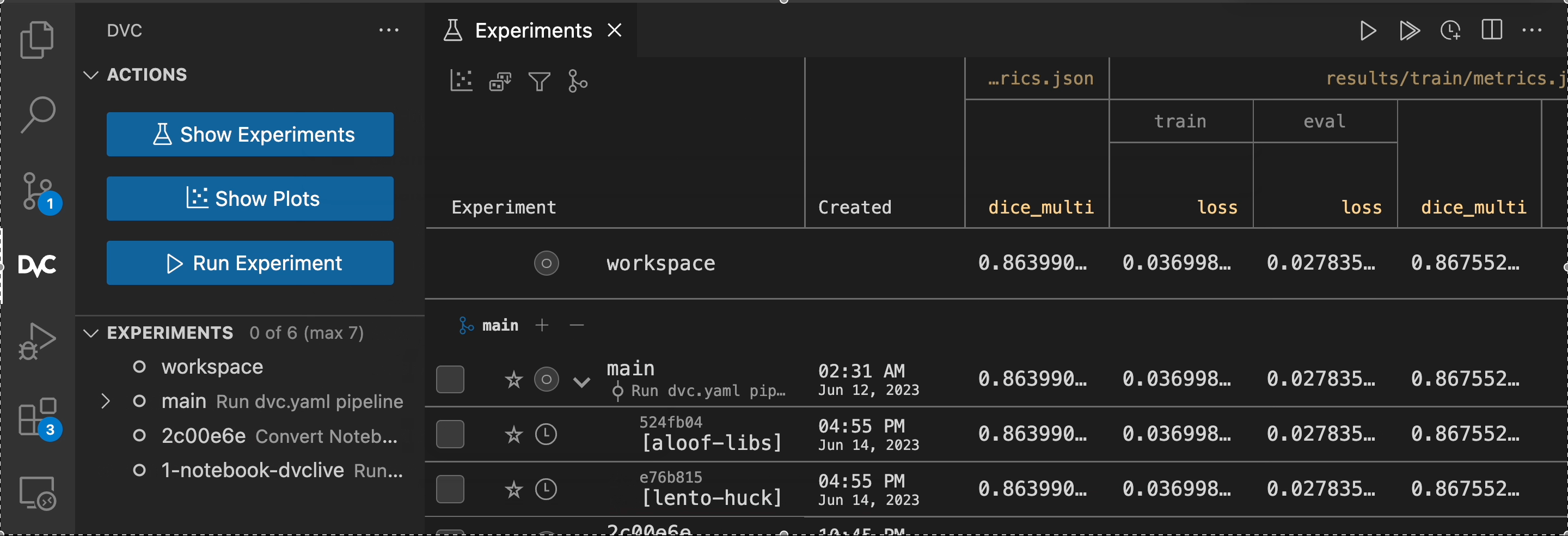
Alternatively, we can setup a hyperparameter grid search:
$ dvc exp run --queue \
-S train.arch='resnet18,shufflenet_v2_x2_0' \
-S 'train.fine_tune_args.base_lr=range(0.001, 0.01, 0.001)'
Queueing with overrides '{'params.yaml': ['train.arch=resnet18', 'train.fine_tune_args.base_lr=0.001']}'.
Queued experiment 'bijou-chis' for future execution.
Queueing with overrides '{'params.yaml': ['train.arch=resnet18', 'train.fine_tune_args.base_lr=0.002']}'.
Queued experiment 'color-meal' for future execution.
Queueing with overrides '{'params.yaml': ['train.arch=resnet18', 'train.fine_tune_args.base_lr=0.003']}'.
Queued experiment 'fusil-chin' for future execution.
...
Queueing with overrides '{'params.yaml': ['train.arch=shufflenet_v2_x2_0', 'train.fine_tune_args.base_lr=0.001']}'.
Queued experiment 'lumpy-jato' for future execution.
Queueing with overrides '{'params.yaml': ['train.arch=shufflenet_v2_x2_0', 'train.fine_tune_args.base_lr=0.002']}'.
Queued experiment 'gypsy-wino' for future execution.
Queueing with overrides '{'params.yaml': ['train.arch=shufflenet_v2_x2_0', 'train.fine_tune_args.base_lr=0.003']}'.
...
Run them all with dvc queue start:
$ dvc queue start
...In most cases, experiment tasks will be executed in the order that they were added to the queue (First In, First Out), but this is not guaranteed.
Their execution happens outside your workspace in temporary directories for isolation, so each experiment is derived from the workspace at the time it was queued.
Queued experiments are processed serially by default, but can be run in parallel
by using more than one --jobs (to dvc queue start more than one worker).
Make sure you're using number of jobs that your environment can handle (no more than the CPU cores).
Note that since queued experiments are run isolated from each other, common stages may be executed multiple times depending on the state of the run-cache at that time.
DVC creates a copy of the experiment's original workspace in .dvc/tmp/exps/
and runs it there. All workspaces share the single project cache,
however.
💡 To isolate any experiment (without queuing it), you can use the --temp
flag. This allows you to continue working while a long experiment runs, e.g.:
$ nohup dvc exp run --temp &
[1] 30473
nohup: ignoring input and appending output to 'nohup.out'Note that Git-ignored files/dirs are excluded from queued/temp runs to avoid
committing unwanted files into Git (e.g. once successful experiments are
persisted). To include untracked files, stage them with git add first
(before dvc exp run) and git reset them afterwards.
To clear the experiments queue and start over, use dvc queue remove --queued.
For more advanced grid searches, DVC supports complex config via Hydra composition.