Machine Learning Experiment Tracking
Making progress on data science projects requires a large number of experiments — attempts at tuning parameters, trying different data, improving code, collecting better metrics, etc. Keeping track of all these changes is essential, as we may want to inspect them when comparing outcomes. Recovering these conditions later will be necessary to reproduce results or resume a line of work.

DVC provides a layer of experiment management features out-of-the-box (no need for special servers or websites). Running DVC Experiments in your workspace captures relevant changesets automatically (input data, source code, hyperparameters, artifacts, etc.).
Other tools tend to focus on experiment navigation by saving metrics and artifacts that result from your experiments, along with fragile links to code revisions. DVC's approach guarantees reproducibility by working on top of Git instead, and not as a separate system.
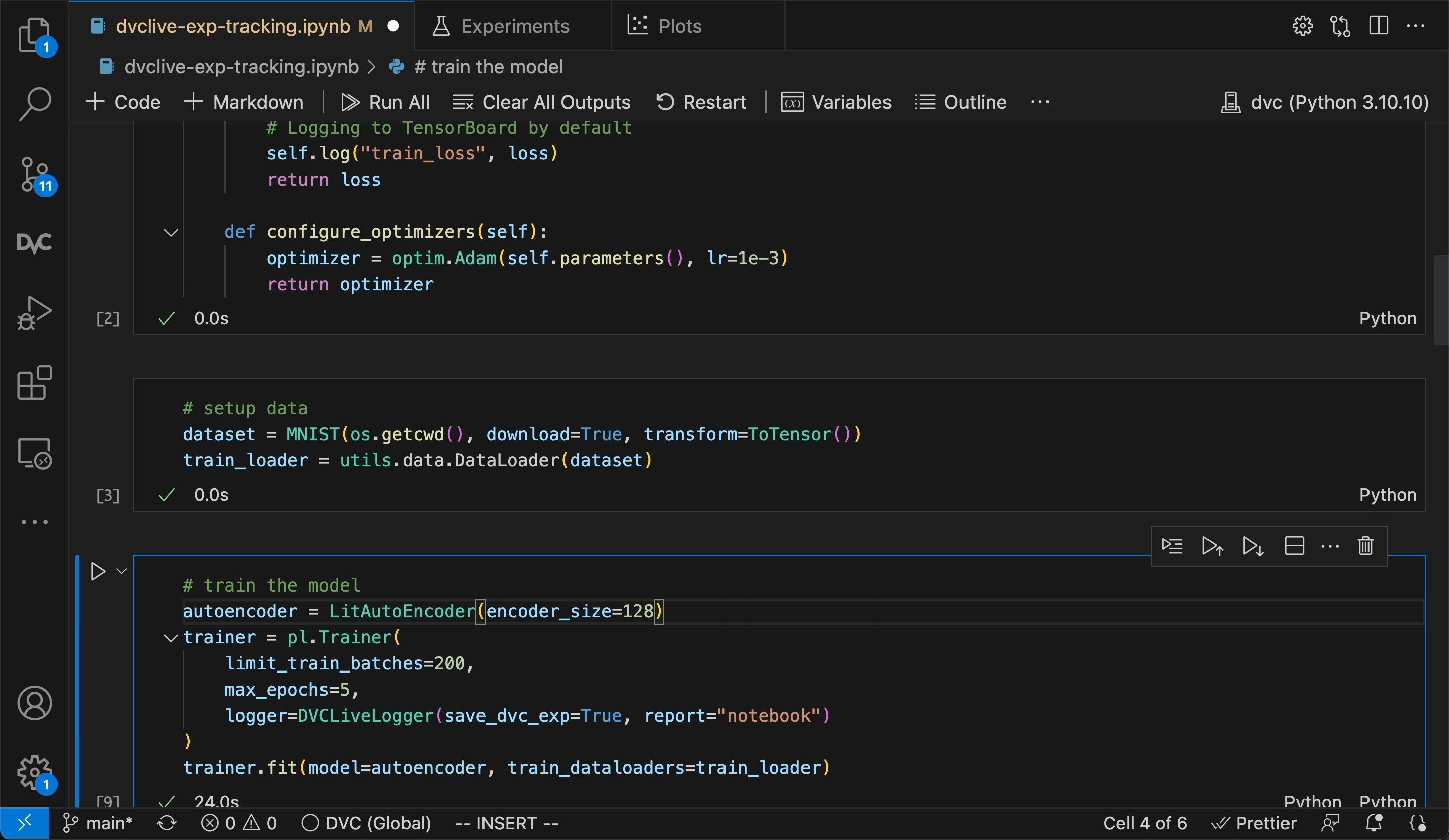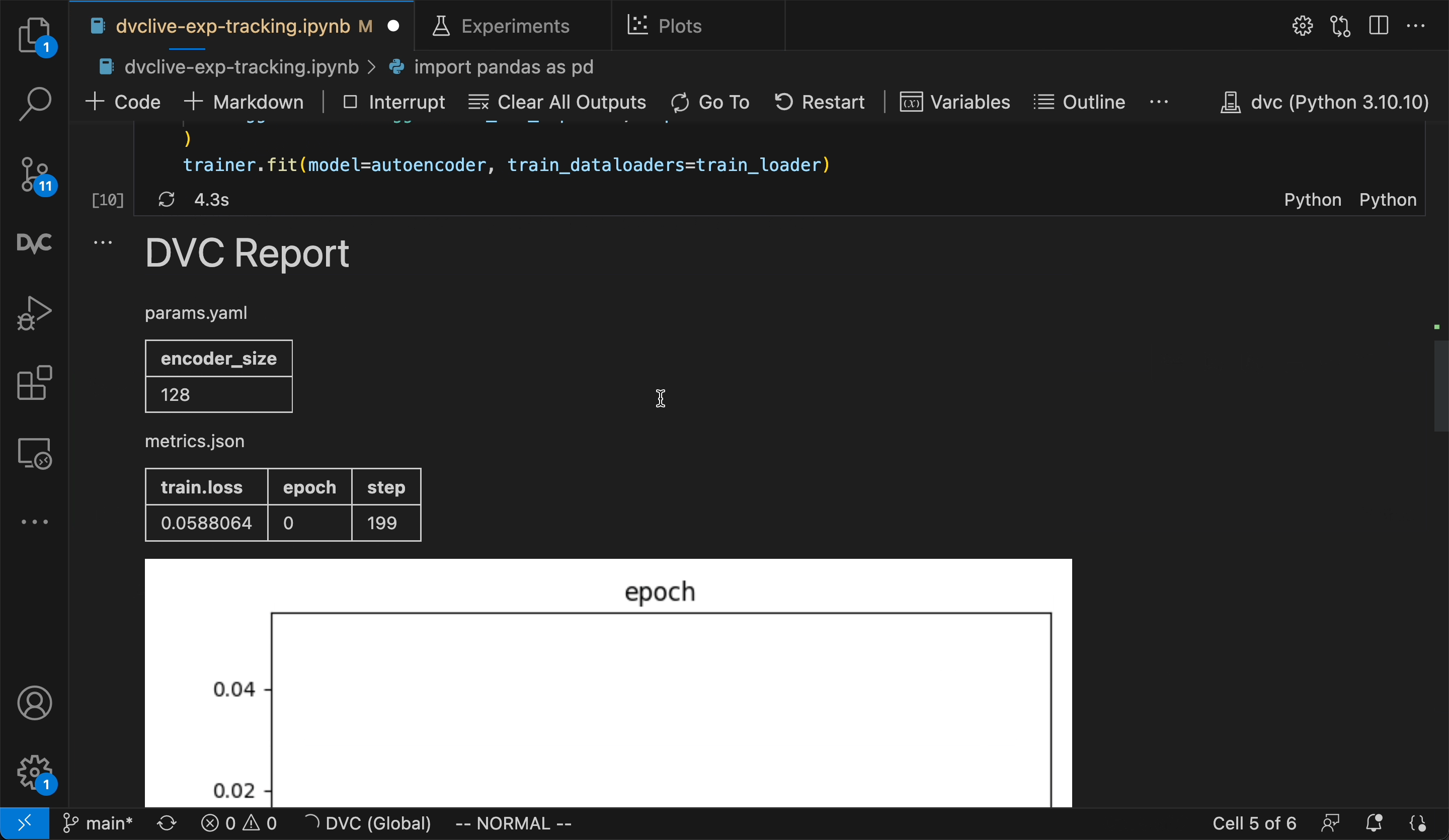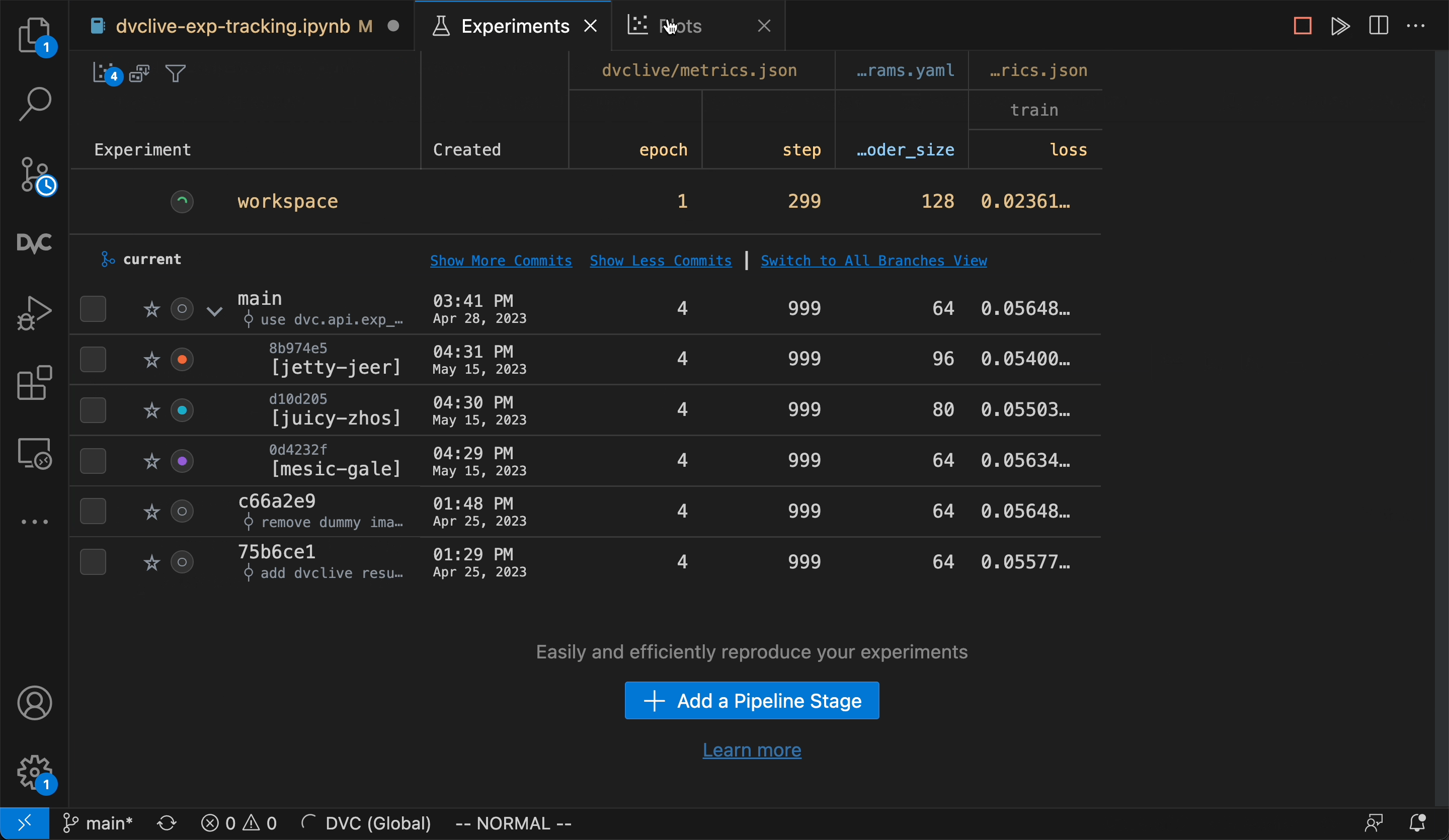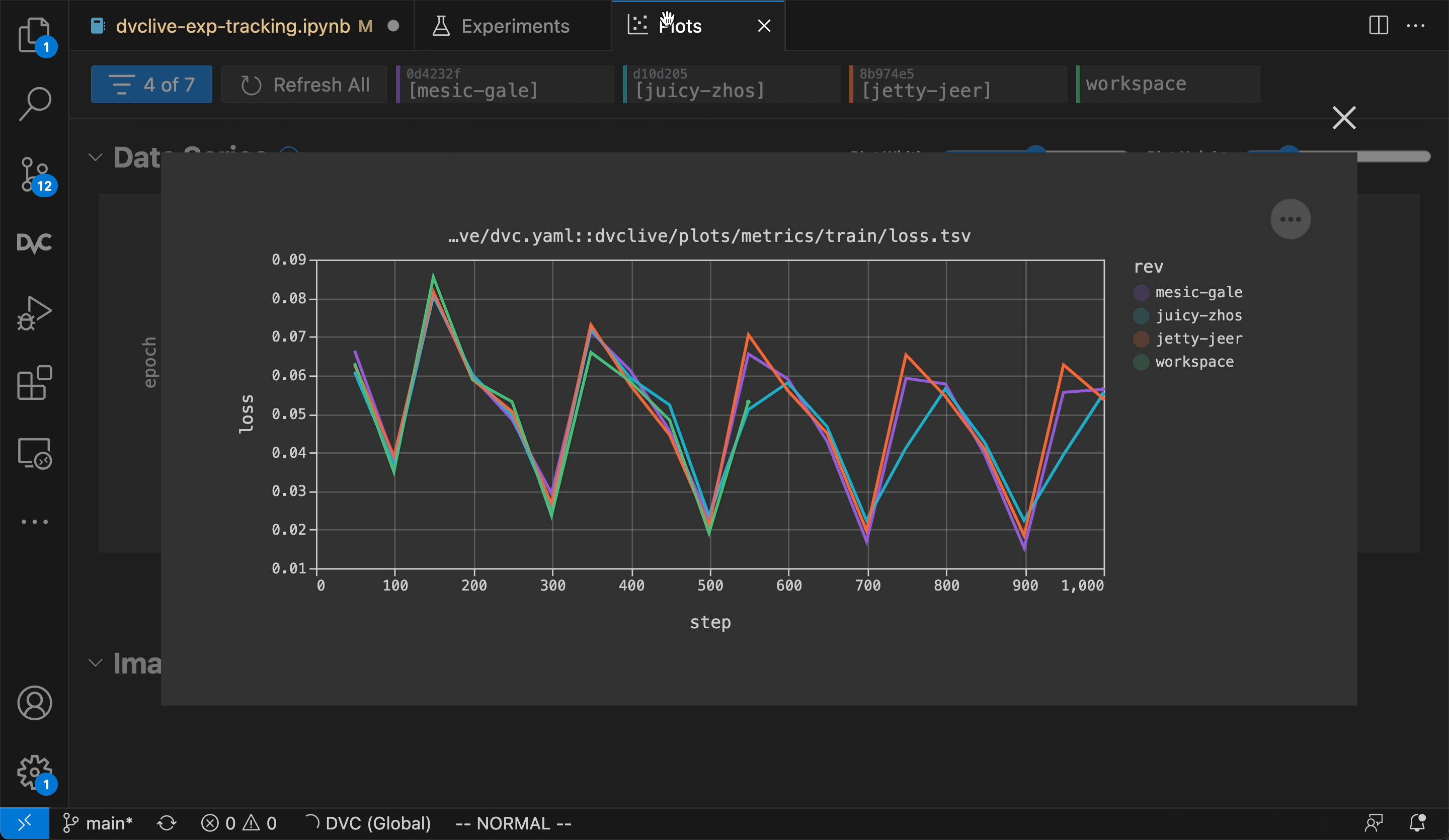 _DVC Experiments are organized along project versions
(Git commits, branches, tags, etc.), and can be compared in the terminal, the
VS Code extension (shown) or DVC Studio.
_DVC Experiments are organized along project versions
(Git commits, branches, tags, etc.), and can be compared in the terminal, the
VS Code extension (shown) or DVC Studio.
When you are ready to share, DVC Studio can be the central hub for your team's projects, experiments, and models. DVC Studio also gives you the power to run experiments in the cloud.
Major benefits of tracking experiments with DVC:
- Quickly iterate on experiment ideas, with automatic bookkeeping of data dependencies, code, parameters, artifacts, ML models, and their metrics.
- Use a controlled execution mechanism; Run one or queue many experiments (and run them in parallel if needed).
- Track live metrics.
- Review and compare results based on params or metrics; Restore them from cache or reproduce them from scratch.
- Adopt or stay on a Git workflow (distributed collaboration) and services such as GitHub.
- Submit pull requests for your experiments, conduct reviews in services like GitHub, and otherwise collaborate on experiments like teams do for code.
Ready to dive in? Get started with experiments!
Among other differentiators (below), DVC Experiments are unique in the space in that they provides a simple yet flexible, local-first experience. Your code is unchanged and you control where data is saved and shared. DVC also improves storage efficiency and saves you time via caching, preventing repetitive data transfers or having to retrain models on-the-fly.
| DVC Experiments | Existing tools | |
|---|---|---|
| UI | IDE and terminal | Web (usually SaaS) |
| Logging | Git-based | Custom formats |
| Storage | Data versioning | Logging artifacts and metrics |
| Execution | dvc exp run | Code API (usually Python) |
| Collaboration | Distributed | Centralized |
💡 Note that other experiment tracking tools can be complementary to DVC, for example for detailed experiment environment logging with specialized visualizations.
Finally, DVC is completely language agnostic, offering the same functionality whether you're using Jupyter notebooks or Scala, CSV data frames or HDFS.