Machine Learning Model Registry
A model registry is a tool to catalog ML models and their versions. Models from your data science projects can be discovered, tested, shared, deployed, and audited from there. DVC Studio model registry enables these capabilities on top of Git, so you can stick to an existing software engineering stack. No more division between ML engineering and operations!
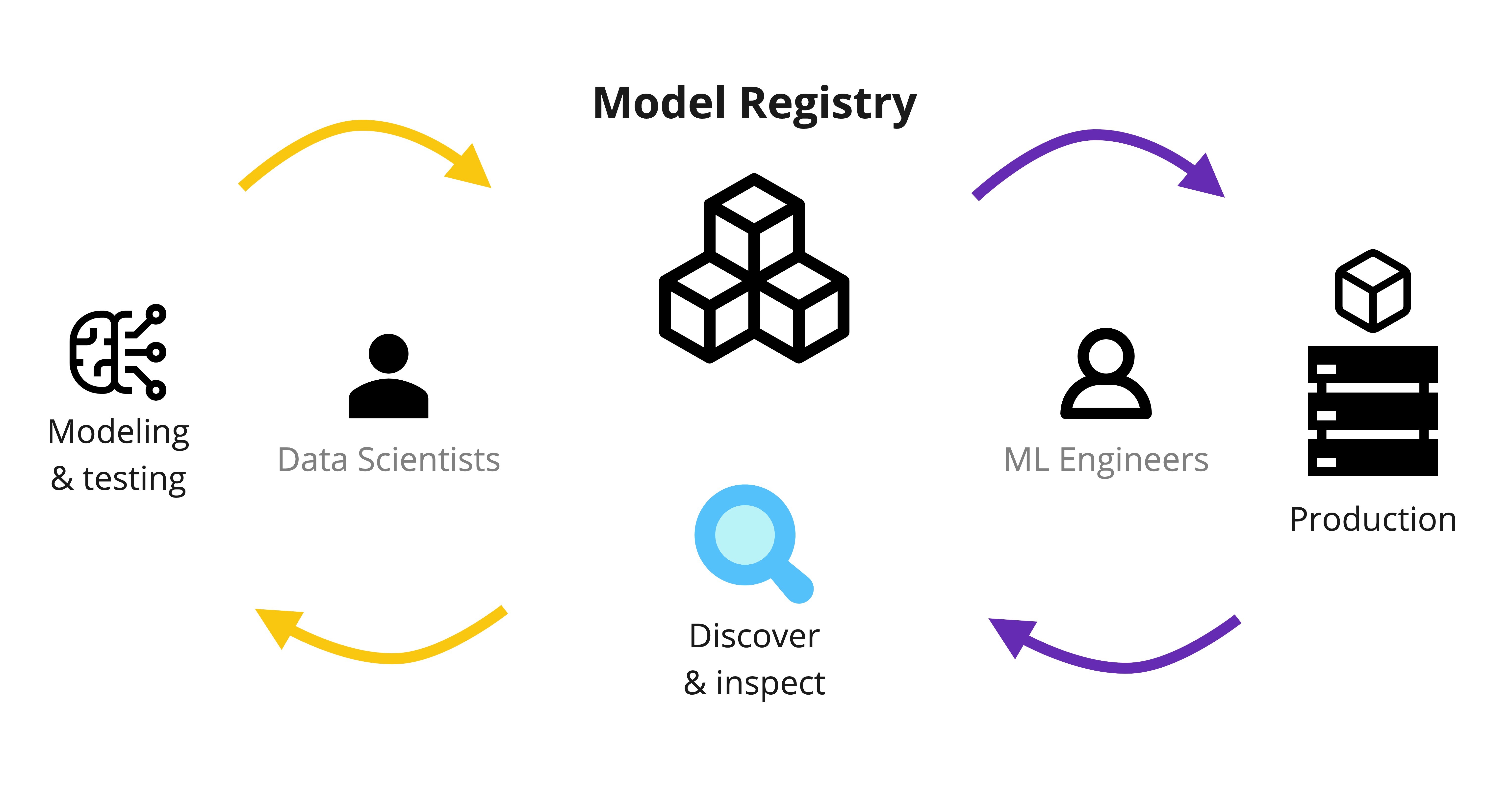
Model registry enables end-to-end workflows:
-
Log your model: Start by logging your model's performance metrics and artifacts. Seamless integration with your existing ML framework allows you to log everything necessary for later model use and evaluation.
-
Compare experiments: Once your models are logged, you can compare metrics, parameters, and plots for different iterations to choose the next model version.
-
Register model versions: After comparing your models, you can register a semantic model version to mark an important iteration. This process of collecting and organizing model versions preserves their data provenance and lineage information, providing a clear history of model development.
-
Assign stage to model: With your model registered, you can manage the lifecycle of your models. Models can be assigned to specific tasks or stages (e.g., dev, shadow, prod), and promoted through these stages based on their performance.
-
Download specific version: To use a specific model version, you can download the latest or requested model version, or the version in the selected stage.
-
Deploy with CI/CD: To enable automation, you can set up a continuous integration/continuous deployment (CI/CD) workflow that publishes or deploys your model. CI/CD can be triggered upon version registration or stage assignment automatically, creating a streamlined process for model deployment.
These steps provide a streamlined workflow from model development to deployment, supporting all stages of ML model lifecycle.
To begin with this integrated approach to managing your ML models, start managing models with DVC!