Fast and Secure Data Caching Hub
Datasets used in data science tend to exceed typical storage and networking capacities. Storage needs to expand rapidly as more people acquire the same data, creating duplication (increasing cost). Valuable time is wasted waiting for downloads in each environment.
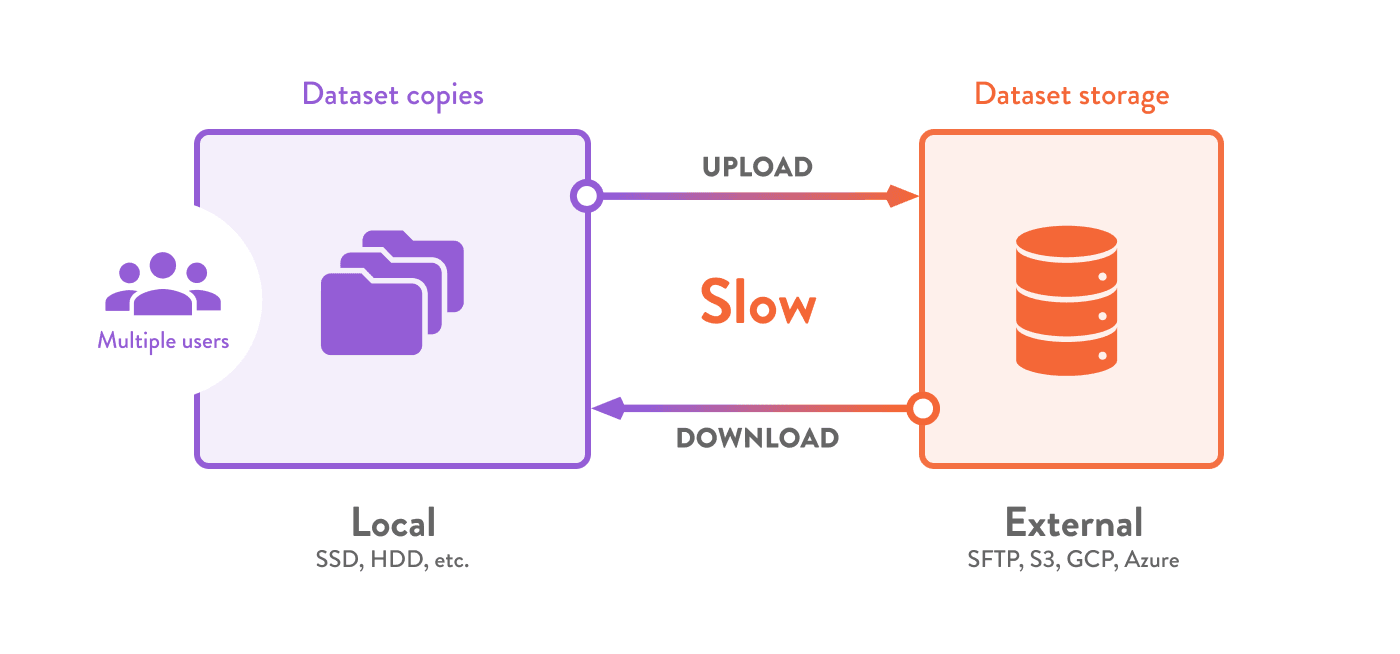
DVC's built-in data caching lets you implement a simple and efficient storage layer globally — for your entire team. This approach can help to
-
speed up data transfers from massive object stores on the cloud, or share data across multiple machines without slowing things down.
-
pay only for fast access to frequently-used data (upgrading your entire storage platform is expensive).
-
avoid downloading data again and duplicating files when multiple people are working on the same data (for example on a shared development server).
-
switch data inputs quickly (without re-downloading) on a shared server used for machine learning experiments.
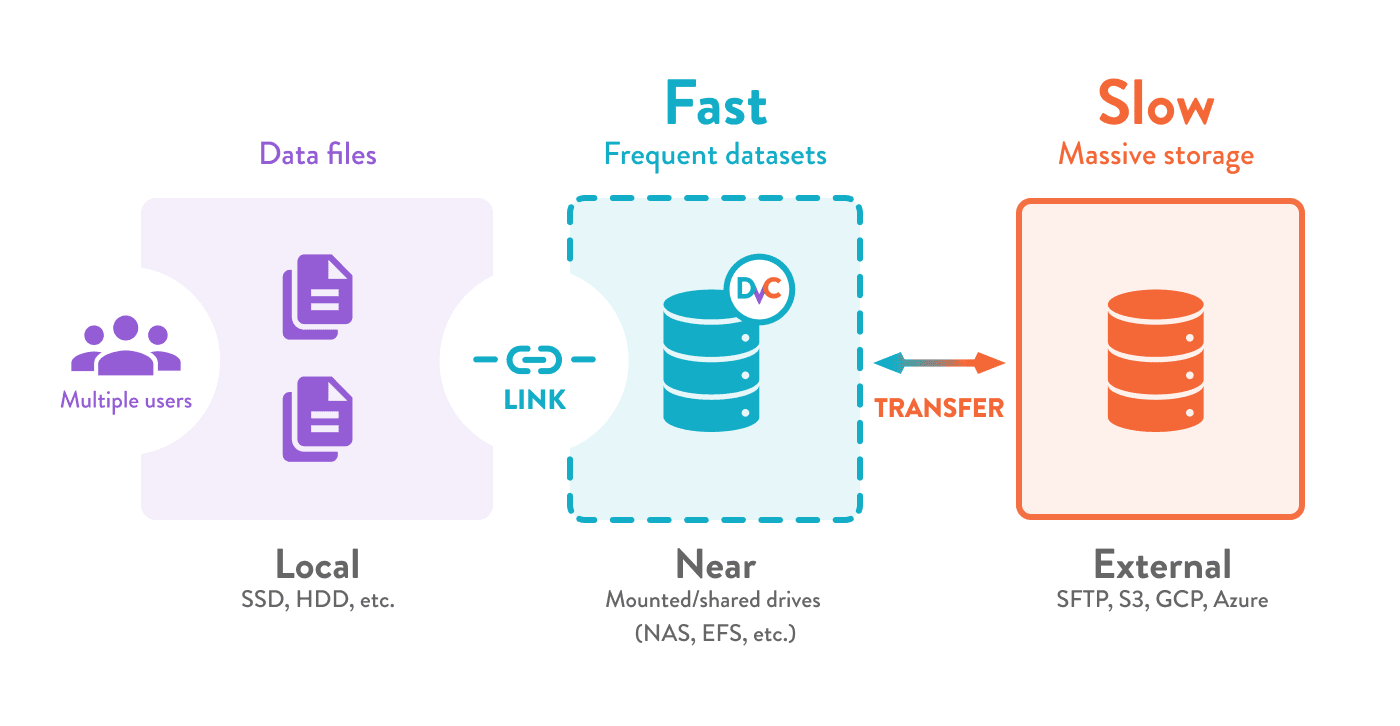
You can have a single storage for all you projects by setting up a shared DVC cache in a near location (network, external drive, etc.). This de-duplicates files across datasets and prevents repetitive transfers by linking your working files and directories. Data security policies can be implemented reliably, as data never leaves the central storage. DVC can also help you back up and share data and ML models on external/remote locations.
Now that your team shares a primary storage, it can be managed independently as part of your infrastructure; provisioned depending on data access speed and cost requirements. You have the flexibility to switch storage providers at any time, without having to change the directory structures or code of your projects.
What's next?
For details about how DVC caches your files and directories, see Structure of the cache directory. If you're completely new to DVC, see our Get Started pages to get familiar with the main features that structured storage and data versioning allow. And check out the following example for a specific solution provided by a layered storage architecture.
Example: Shared development server
Some teams prefer using a single shared machine to run their experiments. This is a simple way to improve resource utilization (quick transfers, central storage, GPU access, etc.). Everyone can still work in a separate workspace (e.g. in their user home folders).

Start by configuring a shared DVC cache. Now when colleagues make changes to
the project, you can get the latest results with dvc checkout. DVC links data
files and directories to your workspace instantly, so data artifacts are never
moved or copied.
$ git pull
$ dvc checkout
A data/new
M data/labels