Versioning Data and Models
Data science teams face data management questions around versions of data and machine learning models. How do we keep track of changes in data, source code, and ML models together? What's the best way to organize and store variations of these files and directories?
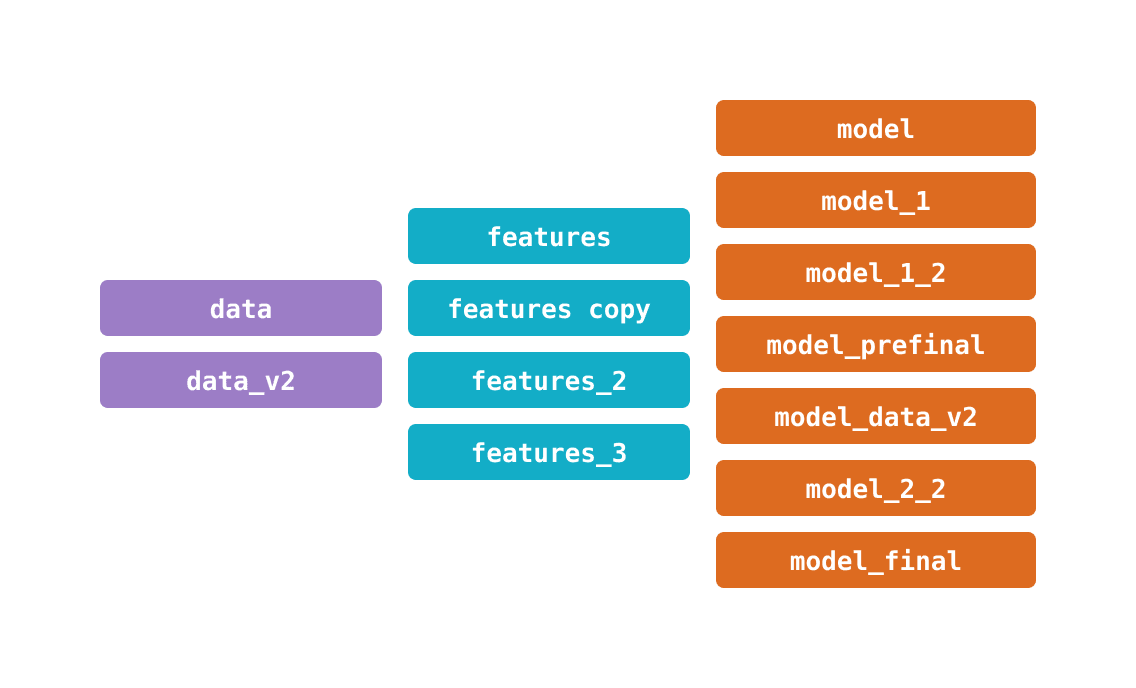
Another problem in the field has to do with bookkeeping: being able to identify past data inputs and processes to understand their results, for knowledge sharing, or for debugging.
Data Version Control (DVC) lets you capture the versions of your data and models in Git commits, while storing them on-premises or in cloud storage. It also provides a mechanism to switch between these different data contents. The result is a single history for data, code, and ML models that you can traverse — a proper journal of your work!
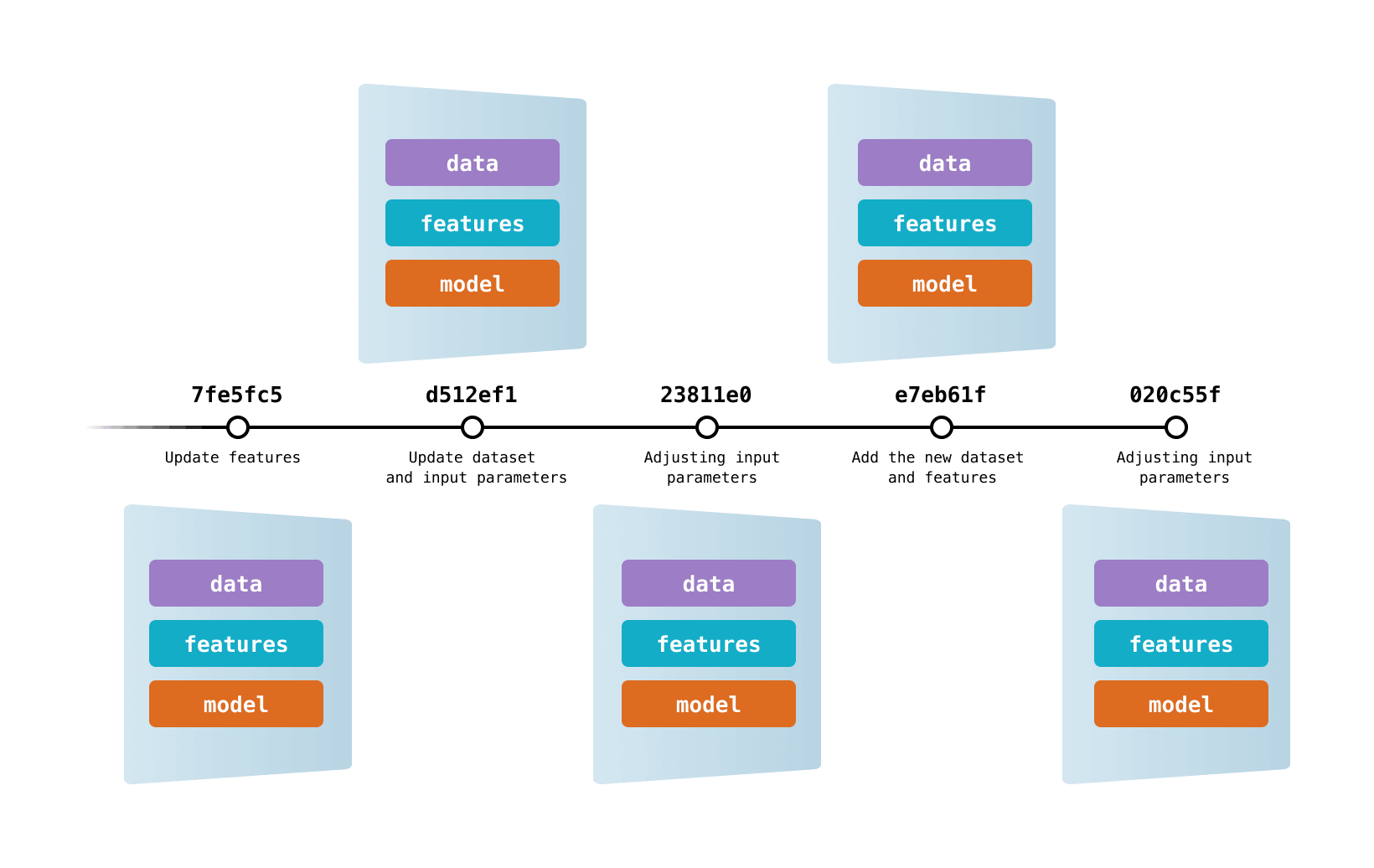
DVC enables data versioning through codification. You produce simple metafiles once, describing what datasets, ML artifacts, etc. to track. This metadata can be put in Git in lieu of large files. Now you can use DVC to create snapshots of the data, restore previous versions, reproduce experiments, record evolving metrics, and more!
👩💻 Intrigued? Try our versioning tutorial to learn how DVC looks and feels firsthand.
As you use DVC, unique versions of your data files and directories are cached in a systematic way (preventing file duplication). The working data store is separated from your workspace to keep the project light, but stays connected via file links handled automatically by DVC.
Benefits of our approach include:
-
Lightweight: DVC is a free, open-source command line tool that doesn't require databases, servers, or any other special services.
-
Consistency: Keep your projects readable with stable file names — they don't need to change because they represent variable data. No need for complicated paths like
data/20190922/labels_v7_finalor for constantly editing these in source code. -
Efficient data management: Use a familiar and cost-effective storage solution for your data and models (e.g. SFTP, S3, HDFS, etc.) — free from Git hosting constraints. DVC optimizes storing and transferring large files.
-
Collaboration: Easily distribute your project development and share its data internally and remotely, or reuse it in other places.
-
Data compliance: Review data modification attempts as Git pull requests. Audit the project's immutable history to learn when datasets or models were approved, and why.
-
GitOps: Connect your data science projects with the Git ecosystem. Git workflows open the door to advanced CI/CD tools (like CML), specialized patterns such as data registries, and other best practices.
In summary, data science and ML are iterative processes where the lifecycles of data, models, and code happen at different paces. DVC helps you manage, and enforce them.
And this is just the beginning. DVC supports multiple advanced features out-of-the-box: Build, run, and versioning data pipelines, manage experiments effectively, and more.