Data Registry
One of the main uses of DVC repositories is the versioning of data and model files. DVC also enables cross-project reusability of these data artifacts. This means that your projects can depend on data from other repositories — like a package management system for data science.
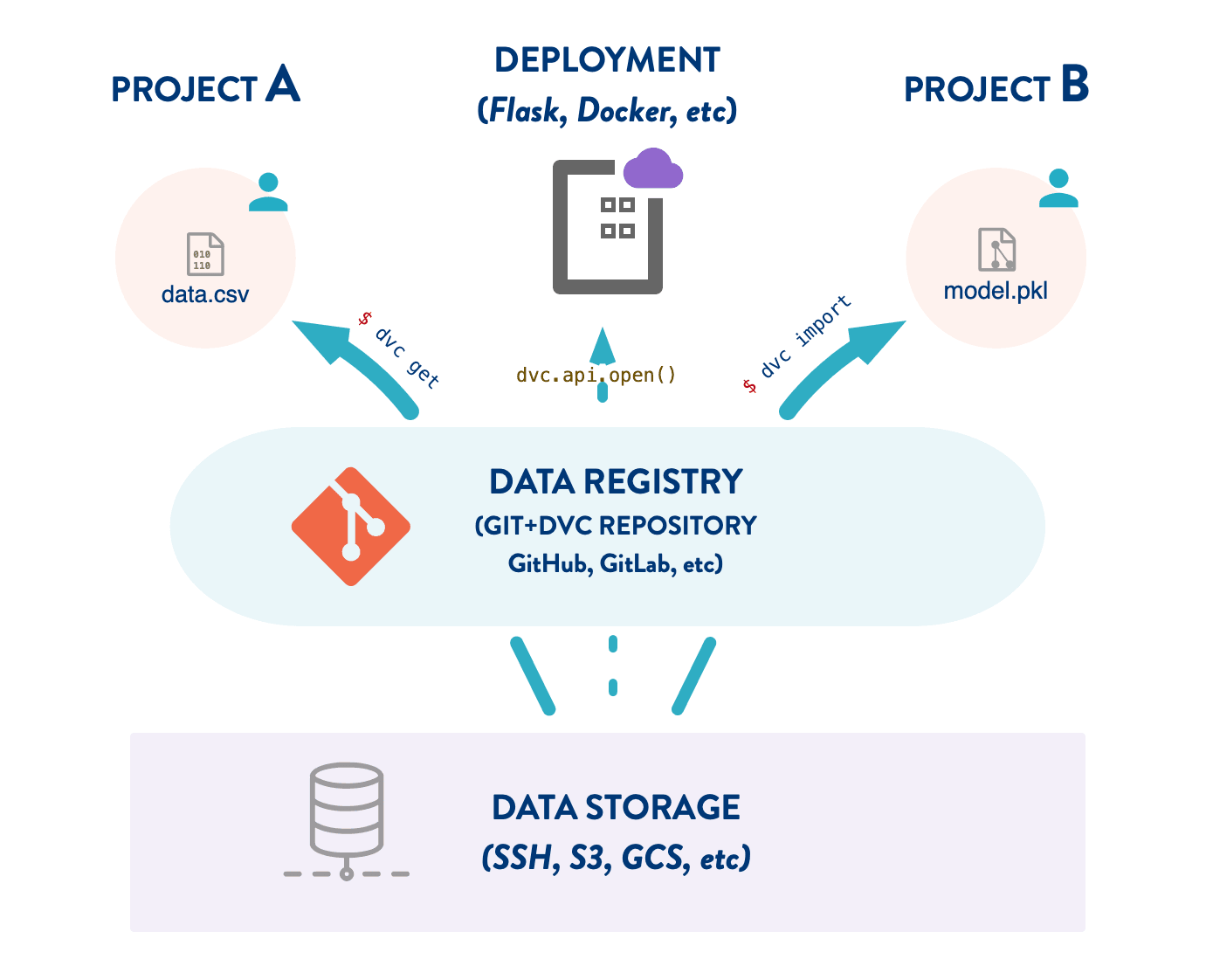
We can build a DVC project dedicated to versioning datasets (or data features, ML models, etc.). The repository contains the necessary metadata, as well as the entire change history. The data itself is stored in one or more DVC remotes. This is what we call a data registry — data management middleware between ML projects and cloud storage. Advantages:
- Reusability: Reproduce and organize feature stores with a simple CLI
(
dvc getanddvc importcommands, similar to software package management likepip). - Persistence: Separating metadata from storage on reliable platforms (Git, cloud locations) improve the durability of your data.
- Storage optimization: Centralize data shared by multiple projects in a single location (distributed copies are possible too). This simplifies data management and optimizes space requirements.
- Data as code: Leverage Git workflow benefits such as having a commit history, branching, pull requests, reviews, and even CI/CD for your data and models lifecycle. Think "Git for cloud storage".
- Security: DVC-controlled remote storage (e.g. Amazon S3) can be configured to limit data access. For example, you can setup read-only endpoints (e.g. an HTTP server) to prevent data deletions or alterations.
👩💻 Intrigued? Try our registry tutorial to learn how DVC looks and feels firsthand.
See also Model Registry.